

Kafka, Confluent Platform e Apache Flink: Uma combinação perfeita ! | Parte III
Olá pessoal !
Devido a pedidos, hoje eu irei incluir dois novos assuntos com exemplos. O KsqlDB e o REST Proxy. Apesar de fugir um pouco do tema, acredito que seja algo bem interessante para aprendermos. Prometo que após o artigo do Rest Proxy, partiremos para o Apache Flink diretamente ! 🙂
KsqlDB
O KsqlDB é um banco de dados projetado especificamente para aplicações de processamento de fluxo em cima do Apache Kafka. Ele é voltado para a construção de aplicativos que processam fluxos de eventos em tempo real. Aqui estão alguns detalhes sobre o ksqlDB:
- Streaming de Eventos: O ksqlDB é conhecido por ser um banco de dados de streaming de eventos. Ele permite que você processe fluxos de dados em tempo real, o que é essencial para cenários como detecção de fraudes e aplicativos baseados no padrão Event Sourcing.
- SQL para Descrição de Tarefas: Uma característica interessante do ksqlDB é que você pode usar SQL para descrever o que deseja fazer em vez de como fazê-lo. Isso facilita a construção de aplicativos nativos do Kafka para processar fluxos de dados em tempo real.
O Flink é uma escolha mais geral e escalável para profissionais altamente especializados em processamento de fluxo, enquanto o ksqlDB é mais acessível e adequado para profissionais que desejam uma abordagem mais simples e baseada em SQL. Porém, o KsqlDB ainda é amplamente usado e tem o seu espaço.
Vamos agora ao que interessa, vamos criar uma STREAM e um TABLE utilizando o KsqlDB. Vamos entender o que cada um deles significa:
- Streams (fluxos):
- Streams são séries ilimitadas de eventos.
- Eles são construídos a partir de tópicos do Apache Kafka.
- Cada evento em um stream é tratado como uma entrada contínua.
- Streams crescem à medida que novos eventos são adicionados.
- Eles são úteis para processamento de fluxo em tempo real, como detecção de fraudes ou análise de eventos.
- Tables (tabelas):
- Tables representam o estado atual de uma chave específica.
- Assim como streams, elas também são construídas a partir de tópicos do Kafka.
- Uma tabela só cresce quando novas chaves são adicionadas.
- Elas são ideais para obter o estado atual de uma chave rapidamente.
- Por exemplo, se tivermos uma tabela com informações sobre a localização de pessoas, ela nos diria onde cada pessoa está no momento.
Em resumo, streams são para eventos contínuos e tables representam o estado atual de uma chave específica. Ambos são fundamentais para o processamento de fluxo no ksqlDB !
Para começarmos, vamos fazer uma pequena modificação no arquivo .properties do conector:
name=tsv.spooldirfile.clients.source
tasks.max=1
connector.class=com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector
input.path=/app/workarea/confluent-spooldir-test/files
error.path=/app/workarea/confluent-spooldir-test/files/error
finished.path=/app/workarea/confluent-spooldir-test/files/finished
input.file.pattern=^tsv-spooldir.*\.tsv$
halt.on.error=false
topic=tsv.spooldirfile.clients
schema.generation.enabled=true
csv.first.row.as.header=true
csv.separator.char=9
offset.flush.interval.ms=10000
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=falseFiz algumas modificações para definir o payload JSON. Assim não teremos problemas ao criar as STREAMs e os TABLES. Crie o novo conector utilizando os mesmos passos do artigo anterior, com esse novo arquivo.
Agora vamos ao que interessa. No Control Center, clique em KsqlDB, depois em ksqldb1:
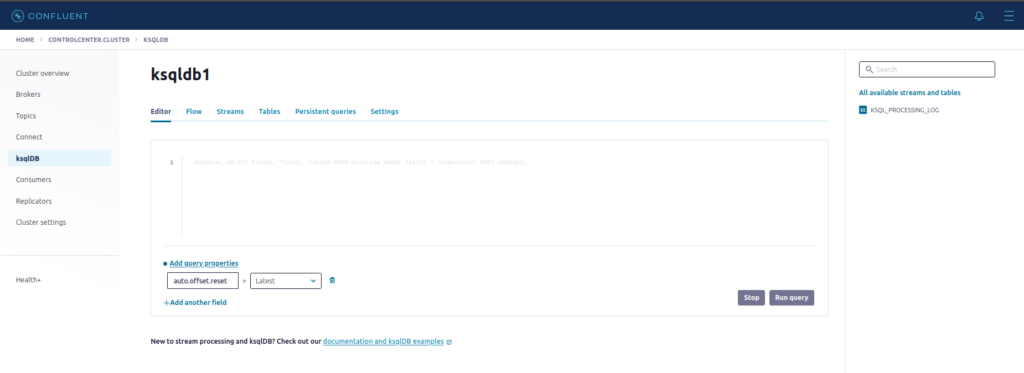
No editor, cole o seguinte código:
CREATE STREAM raw_clients_stream (
id STRING,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
ip_address STRING,
last_login STRING,
account_balance DOUBLE,
country STRING,
favorite_color STRING
) WITH (
KAFKA_TOPIC='tsv.spooldirfile.clients',
VALUE_FORMAT='JSON',
KEY_FORMAT='JSON', -- Usar JSON para suportar chaves compostas
PARTITIONS=1
);Agora clique em Run Query.
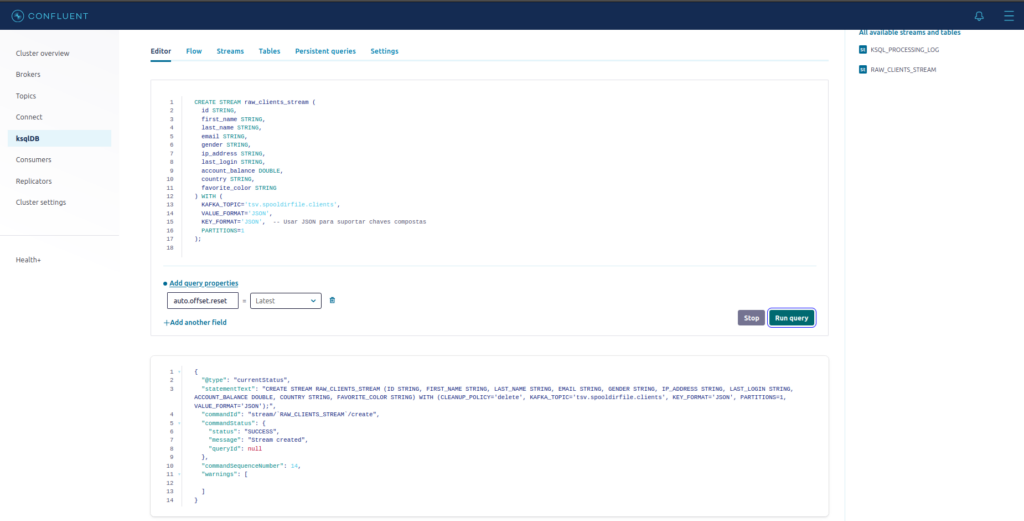
A nossa STREAM foi criada com sucesso !
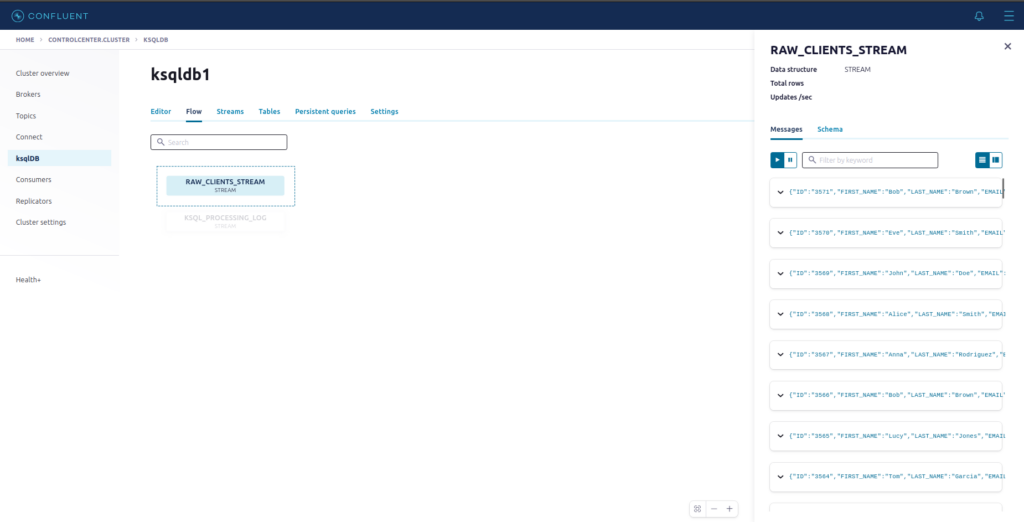
Clique agora na opção Flow e depois em RAW_CLIENTS_STREAM. Agora observe os dados do tópico tsv.spooldirfile.clients fluindo pela stream que criamos !
Clique novamente no Editor, e vamos criar uma nova stream baseada na RAW_CLIENTS_STREAM que criamos acima. Para isso, use utilize o código abaixo:
CREATE STREAM client_stream AS
SELECT
id,
first_name,
last_name
FROM raw_clients_stream;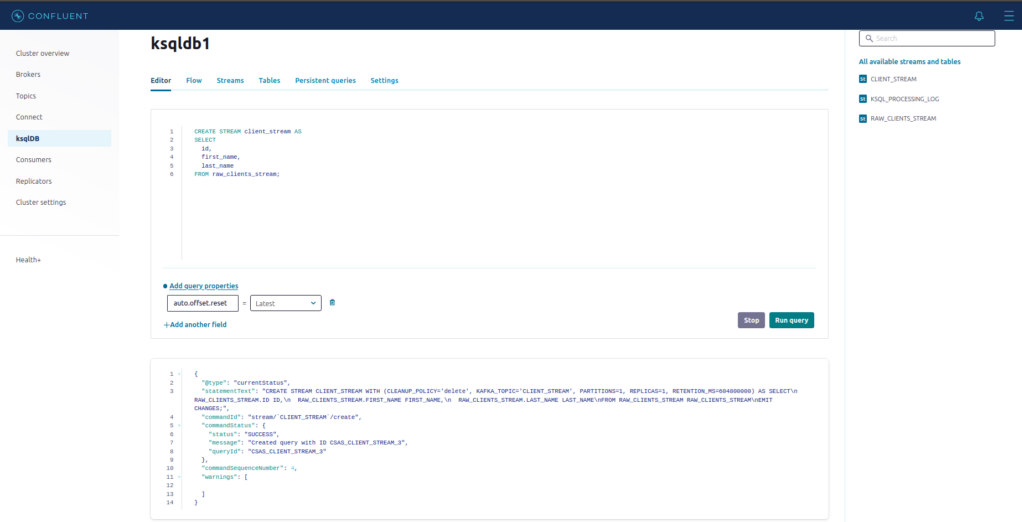
Retorne em Flow e clique em CLIENT_STREAM:
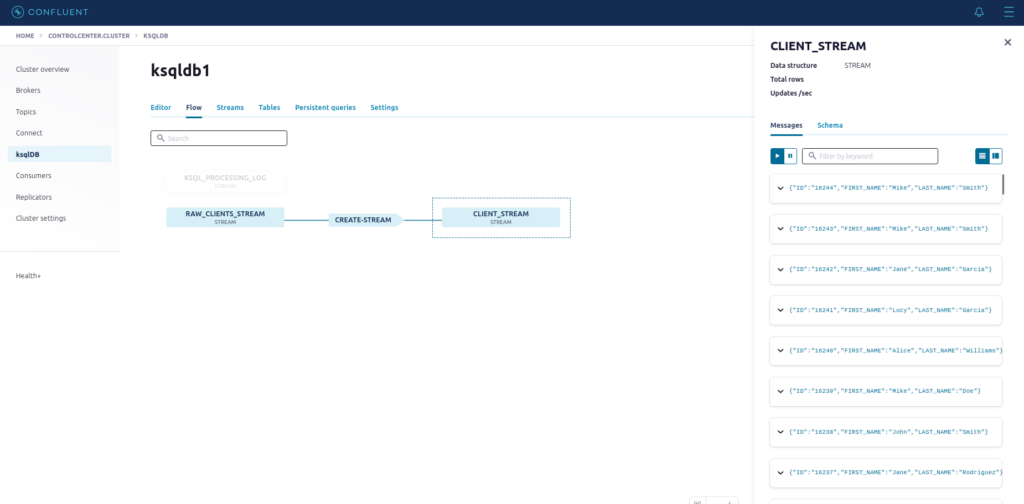
Vamos abrir uma mensagem e ver o seu conteúdo:
{
"ID": "19000",
"FIRST_NAME": "Tom",
"LAST_NAME": "Davis"
}Observe que a nova STREAM que criamos, possui apenas 3 campos.
O próximo passo será criar a nossa tabela, baseada na RAW_CLIENTS_STREAM. Essa tabela guardará sempre o último saldo da conta do cliente, que terá como chave first_name e last_name.
Para isso, use o código abaixo:
CREATE TABLE clients_table WITH (KEY_FORMAT='JSON') AS
SELECT
first_name,
last_name,
LATEST_BY_OFFSET(account_balance) AS latest_account_balance
FROM raw_clients_stream
GROUP BY first_name, last_name;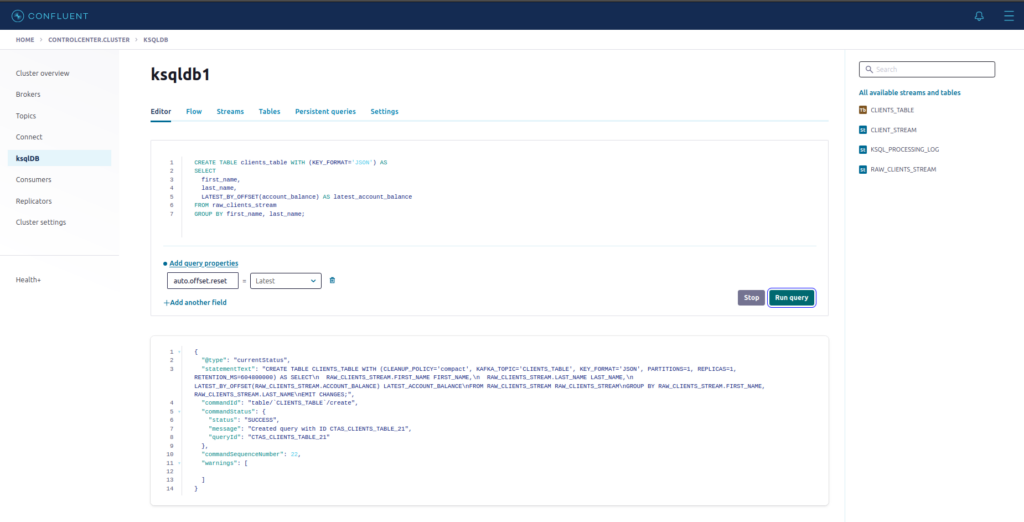
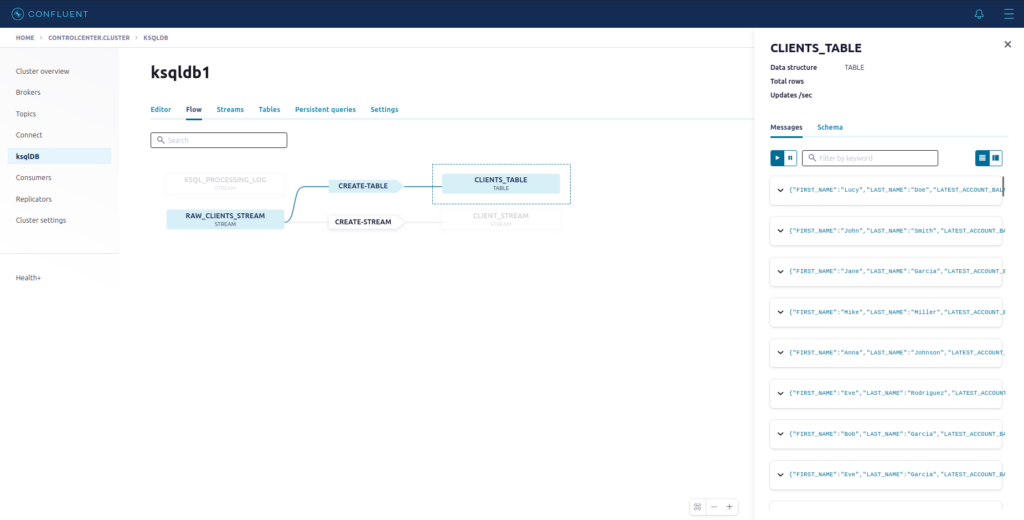
Agora vamos fazer um pequeno SELECT para consultar os nossos dados na tabela CLIENTS_TABLE:
SELECT
first_name,
last_name,
latest_account_balance
FROM clients_table
EMIT CHANGES;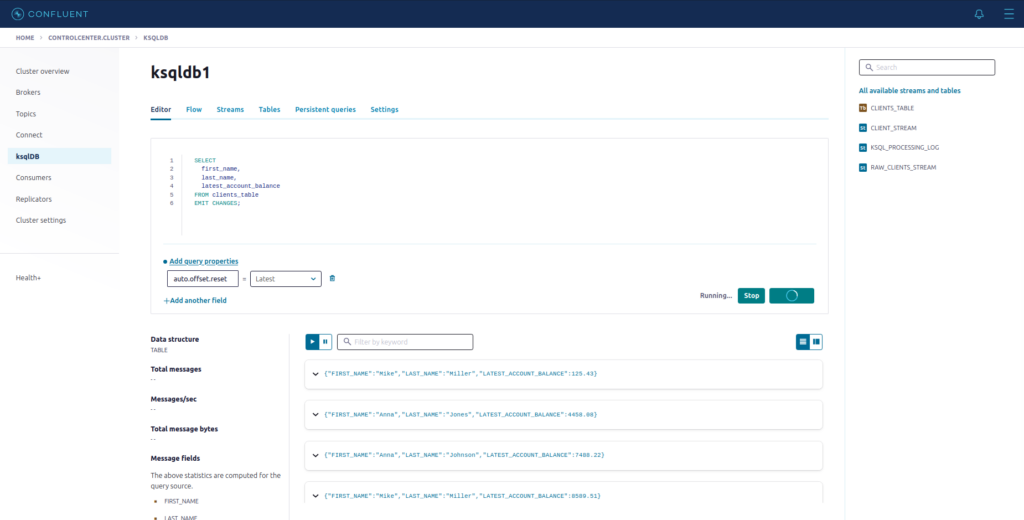
Vamos pegar a posição de saldo de um cliente específico:
SELECT
first_name,
last_name,
latest_account_balance
FROM clients_table
WHERE first_name = 'Jane'
AND last_name = 'Doe'
EMIT CHANGES;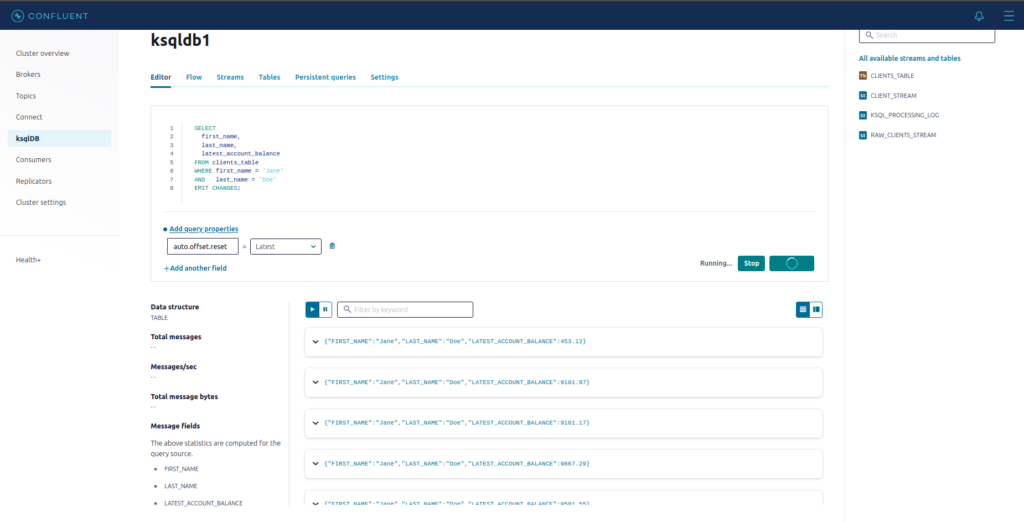
Toda vez que o saldo para este cliente se alterar, será exibidido o registro com o novo valor.
A cláusula EMIT CHANGES no final do SELECT, faz com que a query persista e exiba os dados assim que a condição do WHERE seja cumprida.
O próximo passo agora, é você que decide ! Experimente, teste, erre, acerte, crie cenários e explore toda a capacidade do KsqlDB !
Para aprender mais sobre o KqlDB, inscreva-se neste conteúdo para iniciantes, assista o mini curso sobre STREAMS e acesse a documentação oficial !
E assim terminamos mais um capítulo de nossa saga ! Até o próximo artigo !
Referências