

Oracle Database In-Memory – Primeiros Passos
In-Memory Column Store possibilita que os objetos (tabelas ou partições) sejam armazenados na memória utilizando o formato columnar. Este formato possibilita que scans, joins e aggregates sejam mais rápidos que no formato tradicional (row format). Esta feature não substitui o buffer cache, ela apenas mantém um cópia adicional e consistente do objeto.
Não são necessárias alterações na aplicação para começar a utilizar esta feature, basta apenas alterar algumas configurações do banco de dados.
O In-Memory Column Store é um novo componente da SGA, chamado In-Memory Area.
Ilustração dos 2 formatos:
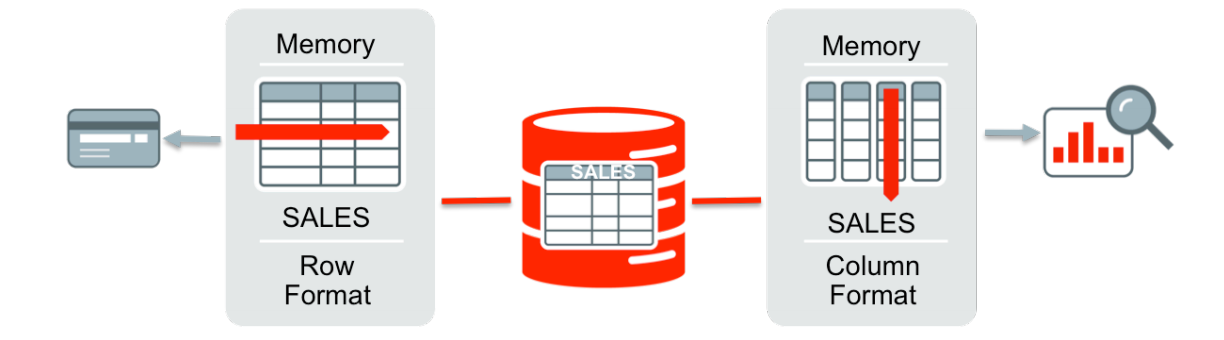
Pela tabela oficial de preços da Oracle, a sua utilização implica em um custo extra de 23K USD por processador.
Para ativar essa feature, tudo que você tem a fazer é verificar se o parâmetro compatible está setado para 12.1.0.2 e alterar o parâmetro inmemory_size para um valor maior que 0.
[oracle@oracle01 ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.2.0 Production on Thu Jul 24 10:24:11 2014
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics
and Real Application Testing options
SQL> show parameter inmemory
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
inmemory_clause_default string
inmemory_force string DEFAULT
inmemory_max_populate_servers integer 1
inmemory_query string ENABLE
inmemory_size big integer 1G
inmemory_trickle_repopulate_servers_ integer 1
percent
optimizer_inmemory_aware boolean TRUEPara verificar os segmentos que estão em memória, podemos utilizar a view V$IM_SEGMENTS.
SQL> Select owner, segment_name name, populate_status status From v$im_segments;
no rows selected
SQL> Select table_name, cache, inmemory_priority, inmemory_distribute, inmemory_compression from dba_tables where table_name='EMPLOYEES';
TABLE_NAME CACHE INMEMORY INMEMORY_DISTRI INMEMORY_COMPRESS
-------------------- -------------------- -------- --------------- -----------------
EMPLOYEES NVamos alterar a tabela para utilizar o in-memory:
SQL> Alter table hr.EMPLOYEES inmemory;
Table altered.
SQL> Select table_name, cache, inmemory_priority, inmemory_distribute, inmemory_compression from dba_tables where table_name='EMPLOYEES';
TABLE_NAME CACHE INMEMORY INMEMORY_DISTRI INMEMORY_COMPRESS
-------------------- -------------------- -------- --------------- -----------------
EMPLOYEES N NONEAUTO FOR QUERY LOWExecutando um select na tabela:
SQL> select /*+ full(EMPLOYEES) */ count(*) from hr.EMPLOYEES;
COUNT(*)
----------
1807872Verificando os segmentos carregados em memória:
SQL> Select owner, segment_name name, populate_status status From v$im_segments;
OWNER NAME STATUS BYTES_NOT_POPULATED
-------------------- ------------------------------ --------- -------------------
HR EMPLOYEES COMPLETED 0Mais uma view útil:
SQL> select * from V$INMEMORY_AREA;
POOLALLOC_BYTES USED_BYTES POPULATE_STATUS CON_ID
-------------------------- ----------- ---------- -------------------------- ----------
1MB POOL 854589440 22020096 DONE 0
64KB POOL 201326592 327680 DONE 0Neste post você viu uma pequena introdução sobre in-memory. Irei trabalhar na publicação em breve de artigos mais completos e com exemplos práticos.
Referência
Abraço