

Índices B-Tree – Considerações básicas
O artigo propõe de uma forma básica e simplista alguma teoria fundamental da indexação em Oracle para podermos entender um pouco mais sobre a material.
A abordagem vai ser basicamente um misto de teoria e prática sobre índices Btree.
Para iniciar criaremos uma tabela e um índice de seguida:
SQL> create table indx_con1 as select rownum as R0, mod(rownum, 200) as R1 from dual connect by level <= 200000;
Table created.
SQL> create index i1 on indx_con1(R0);
Index created.A primeira análise a fazer será na tabela dba_indexes para analisarmos os dados relativos ao índice que acabámos de criar. Vejamos:
SQL> select blevel, leaf_blocks, clustering_factor from dba_indexes where index_name = 'I1';
BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
---------- ----------- -----------------
1 445 372Isto significa que o índice consiste basicamente apenas pelo Root Block (nó pai), informação dada pelo BLEVEL=1 (profundidade da árvore), por 445 leaf blocks (nós filhos).
Como tal se necessitarmos de ler uma determinada entrada do índice será necessário ler primeiramente o root block (nó pai) e posteriormente o leaf block especifico (nó filho). No total serão 2 leituras.
Vamos então verificar se esta explicação coincide com aquela que o CBO nos fornece.
SQL> set autotrace traceonly explain statistics
SQL> select * from indx_con1 where R0=22;
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
591 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processedPodemos tirar várias ilações sobre os resultados anteriores nomeadamente:
1 – O custo de aceder ao índice (e apenas ao índice) é de 1, significa que o CBO sabe que a profundidade da árvore é 1 (BLEVEL=1), o índice é pequeno logo o root block (nó pai) está em cache e como tal é excluido do cálculo do custo.
2 – O custo TOTAL do plano (e não apenas de ler a entrada no índice) é 2 (ver Cost no Id 0 no plano), ou seja, dado que o root block está excluído do custo, é necessário uma leitura para o leaf block (nó filho) e outra leitura para ler o bloco na tabela, pois neste caso e dada a query executada apenas a leitura do índice não é suficiente pois não contem todas as colunas que pretendemos devolver.
3 – O número estimado de linhas a devolver é 1 (ver coluna Rows).
4 – O número de consistent gets é 4: 1 para ler o root block (nó pai em cache), 1 para ler o leaf block (nó filho), 1 para ler o table block (acesso à tabela) e por fim mais 1 pois o indice não é unique e é necessário perceber se há mais registos a retornar.
Ainda numa versão mais profunda no índice criado anteriormente (i1). O mecanismo aplicado consegue com muito detalhe dar-nos informações interessantes sobre a constituição do índice B-Tree.
O evento associado é o treedump e permite a partir de um object_id que neste caso vai ser um índice obter um ficheiro de trace com o súmario do índice. Vejamos:
SQL> select object_id from user_objects where object_name = 'I1';
OBJECT_ID
----------
73897
SQL> alter session set events 'immediate trace name treedump level 73897';
Session altered.Viajando até ao directório que contem o trace (ver parametro user_dump_dest) temos:
----- begin tree dump
branch: 0x415129 4280617 (0: nrow: 445, level: 1)
leaf: 0x41512a 4280618 (-1: nrow: 485 rrow: 485)
leaf: 0x41512b 4280619 (0: nrow: 479 rrow: 479)
leaf: 0x41512c 4280620 (1: nrow: 479 rrow: 479)
leaf: 0x41512d 4280621 (2: nrow: 479 rrow: 479)
leaf: 0x41512e 4280622 (3: nrow: 479 rrow: 479)
....
leaf: 0x41543c 4281404 (441: nrow: 449 rrow: 449)
leaf: 0x41543d 4281405 (442: nrow: 449 rrow: 449)
leaf: 0x41543e 4281406 (443: nrow: 16 rrow: 16)
----- end tree dumpComo foi dito o ficheiro gerado contém a estrutura do índice, nomeadamente uma linha no trace por cada bloco no índice. Estas linhas estão ordenadas conforme a estrutura da árvore e os números hexadecimais/decimais apresentados são o endereço do bloco.
Vamos então tentar entender o resultado deste dump ao índice:
- A primeira linha representa o root block (nó pai) com profundidade 1 (blevel=1). De lembrar que este índice é apenas (é pequeno) constituido pelo nó pai e pelos nós filhos.
- O nrow=445 significa que no root block (nó pai único) existem 445 apontadores para os nós filhos, assim cada vez que for necessário ler o índice, no root block existirá directamente o apontador para o leaf block correspondente.
De notar e muito _importante_ que numa árvore mais complexa (ou seja blevel > 1), este valor teria outro significado, ou seja, o nrow do root block seria o número de apontadores para os branch blocks. Usando uma imagem será mais fácil de entender:
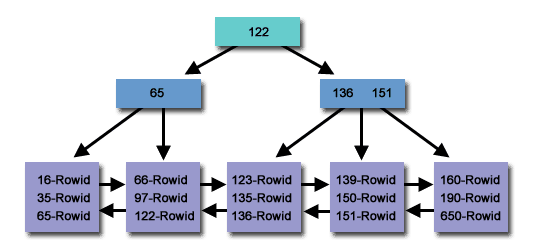
Neste exemplo o root block (denominado aqui 122, não importa o valor) teria um nrows=2, ou seja teria dois apontadores para os nós filhos que neste caso são branch blocks.
Voltando ao nosso exemplo:
- A segunda linha que começa por um estranho -1 (tanto quanto percebi, a contagem inicia em -1 para denominar o primeiro bloco seja branch ou leaf) representa o primeiro leaf block, notado também pois não há level, pois não faz sentido nos leaf blocks.
- O rrow e o nrow nos leaf blocks definem respectivamente o número de linhas no bloco e o seu tamanho no block row directory (u basicamente é um conjunto de informação que diz ao Oracle em cada bloco onde cada linha começa e termina).
De notar também que o rrow = nrow em todos os blocos significa que não houve block split, pois não foi feito nenhum insert após o índice ter sido criado.
- Por fim, a última linha (443) é o último leaf block e como podem ver pelo nrow e pelo rrow não está completo (cheio), pois o valor de 16 é aquém do suportado nos blocos anteriores. Num insert posterior este valor vai concerteza mudar.
Espero que tenha sido claro, e não usem a metodologia “vou-criar-o-índice-e-depois-logo-se-vê-se-melhora-a-performance” 🙂
Artigos originais em: www.lcmarques.com
Abraço