

Introdução ao Oracle Data Guard
Olá pessoal, o André escreveu um artigo sobre a instalação do Oracle Data Guard que me inspirou a escrever sobre o conceito em si. Esse artigo será somente conceitual. Assim, quando você terminar de ler o meu, pode aplicar o conhecimento na prática imediatamente seguindo os passos do artigo do André.
Introduzido na versão 7 o Data Guard tem como principal função a proteção de dados e alta disponibilidade. Desde lá ele passou por uma série de melhorias como Fast-Start Failover 10gR2, Snapshot Standby 11R1, Automatic Block Repair 11gR2, Fast Sync 12R1, etc. Este artigo abordará principais features e conceitos até da versão 12.1.0.2.
Primary Database
Todo Oracle Data Guard possui um database de produção que é conhecido como PRIMARY DATABASE que funciona na role Primary Role. Ele é o database acessado pelas sessões normalmente, pode ser single-instance ou Oracle RAC.
Standby Database
O Data Guard precisa ter no minimo de 1 até 30 standbys configurados. Uma vez criado, o Data Guard mantém cada standby database sincronizado com o primary database através da transmissão de online redo logs e aplicando os redos no standby database. O standby database pode ser single-instance ou Oracle RAC.
Existem 3 tipos de standby:
Physical Standby Database – É uma cópia idêntica do primary database com as estruturas de discos também idênticas. Ele é sincronizado através do Redo Apply que faz o recover dos online redo logs recebidos do primary database e aplica os redos no physical standby database. Desde a versão 11.1 o physical standby database pode receber e aplicar online redo logs enquanto ele está aberto para read-only (feature Active Data Guard). A partir da versão 11.2.0.1 você pode aplicar critical patches updates e patch sets updates no standby database (veja a nota 1265700.1).
Logical Standby Database – Contém as mesmas informações do primary, mas a estrutura física e sua organização pode ser diferente. Ele é sincronizado com o primary database através do SQL Apply que transforma os dados de redos recebidos do primary database em comandos SQL e os executa no standby. O Logical Standby Database permite você fazer upgrade de versões e releases com pouquíssimo downtime, ele pode ser usado em conjunto com o physical database simultaneamente. (Veja a nota 949322.1). O SQL Apply usa processos background para aplicar as mudanças feitas no primary database no logical standby. É dividido em duas fases Log Mining e Apply Processing.
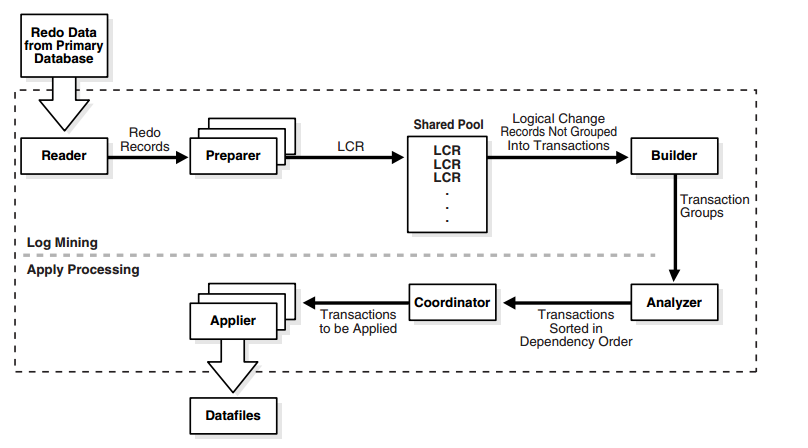
Durante o Log Mining:
READER: O processo READER lê os registros de redo dos archived redo log files ou standby redo log files.
PREPARER: Converte os blocos dos registros de redo em logical change records (LCRs), vários processos PREPARER podem ser ativos para um redo log file. Os LCRs ficam na SGA no local conhecido como LCR Cache.
BUILDER: Agrupa LCRs em transações e efetua outras tarefas como gerenciamento de memória na LCR Cache, efetua checkpoints para o SQL Apply reiniciar e filtra alterações não necessárias.
Durante o Apply Processing
ANALYZER: Identifica as dependências entre transações diferentes.
COORDINATOR: Também chamado de (LSP) designa transações para diferentes appliers e coordinates entre eles para garantir que as dependências entre as transações sejam respeitadas.
APPLIER: Aplica as transações no logical standby sobre a supervisão do coordinator process.
Eles não são afetados pelo resource manager.
O SQL Apply categoriza as transações em duas classes: small e large.
Small transactions: O SQL Apply inicia aplicando os LCRs que pertencem as small transactions uma vez que encontrou o registro do commit para aquela transação no redo log file.
Large transactions: O SQL Apply quebra large transactions em pequenos pedaços chamados transacitons chunks e inicia a aplicação dos chunks antes de encontrar o commit da transação no redo log file. Isso é feito para reduzir a quantidade de memória no LCR Cache e o tempo de failover. Se não houvesse a quebra das large transactions em pequenos pedaços o SQL Loader que lê 10 milhões de linhas, cada uma com 100 bytes por exemplo, poderia usar mais de 1gb de memória no LCR Cache, se a memória não fosse suficiente no LCR Cache (menor que 1gb) isso resultaria em swap. Se o SQL Apply não inciar a aplicação de mudanças relacionadas a 10 milhões de linhas do SQL Loader antes de encontrar um commit para a transação ele pode parar um role transition pois um switchover ou faiolver que é iniciado depois de uma transação ser commitada não pode terminar até o SQL Apply ter aplicado a transação no logical standby. Apesar do uso de transaciton chunks a performance do SQL Apply pode degradar quando processar transações que mude mais de 8 milhões de linhas. Em transações maiores que 8 milhões de linhas SQL Apply usa segmentos temporários para organizar alguns metadados internos necessários para processar a transação. Você vai precisa alocar espaço suficiente para o SQL Apply processar transações com mais de 8 milhões de linhas. Todas as transações são categorizadas inicialmente como small transactions e o SQL Apply determina quando re-categorizar as transações entre small ou large dependendo do consumo de memória pelos LCRs de uma transação.
Considerações de Restart.
Modificações feitas no logical standby não são persistentes até que o registro de commit da transação seja extraído do redo log files e seja aplicado no logical standby. Assim, toda vez que o SQL Apply é parado, propositalmente ou em caso de falha, o SQL Apply volta para a transação extraída mais recente que não tenha sido commitada. Quando a transação causa pouco trabalho, mas continua aberta por um longo período de tempo, reiniciar o SQL Apply desde o início pode ser muito custoso porque SQL Apply pode ter que extrair um grande número de archive redo logs que não são mais necessários, para serem reiniciadas são automaticamente deletadas pelo SQL Apply. DDL, DML em paralelo e direct-path loads vão fazer com que o RESTART_SCN da view V$LOGSTDBY_PROGRESS avance durante uma carga de dados.
Considerações sobre DML Apply
O SQL Apply segue algumas características quando aplica transações DML que afetam o throughput e a latência no logical standby.
Batch updates ou deletes feito no primary database onde um único comando resulta em várias linhas alteradas são aplicados como modificações individuais no logical standby. Assim, é indispensável que cada tabela gerenciada pelo SQL Apply tenha uma unique key ou primary key. Inserts com direct path feitos no primary database são aplicadas usando o INSERT convencional no logical standby. Comandos DML em com parallel não são executados com parallel no logical standby.
Considerações de DDL apply
O DDL apply segue algumas características quando aplicado DDL transactions que afetam o throughput e latência do logical standby. DDL transactions são aplicadas serialmente no logical standby. O uso de CTAS no primary insere as linhas no logical standby com o INSERT convencional. Durante um comando DDL como ALTER TABLE hr.employees ADD (start_date date default sysdate); a função sysdate vai pegar a hora do logical standby database ao invés do primary pois é uma função e não um valor literal. Fazendo com que as tabelas tenham valores distintos.
Snapshot Standby Database – É um banco de dados totalmente atualizável. Assim como o physical ou o logical standby o snapshot database recebe e armazena os online redo logs do primary database. Porém, diferente deles, o snapshot standby não aplica os online redo logs que recebe, eles só são aplicados quando o snapshot é convertido em physical database depois de descartar qualquer alteração feita durante sua role de standby spanshot. Por exemplo, ele pode ser usado como um ambiente de teste mais próximo de produção de segunda à sexta e aos finais de semana ser convertido em physical standby para atualizar as mudanças que ocorreram no primary database. O tempo de recover em relação a primary é proporcional a quantidade de redo que precisa ser aplicada.
Far Sync Instance – O Far Sync Instance é um destino remoto do Data Guard que recebe online redo logs do primary database e então envia esses redos para outro membro do Data Guard. O Far Sync Instance possui um control file e envia os online redo para os standby redo logs (SRLs) e arquiva esses SRLs para o local dos archives redo logs. Porém, um Far Sync Instance só possui isso de similar com os restantes dos standbys pois ele não possui data files, não pode ser aberto, não pode ter redo apply nele e nunca será convertido para nenhuma role. Ele é usado quando você possui Data Guard em localidades geográficas muito grandes. Por exemplo, você possui o Primary no Brasil, o physical no Chile e coloca um Far Sync no México, para então enviar para o Logical nos EUA. Isso diminui a latência entre sites.
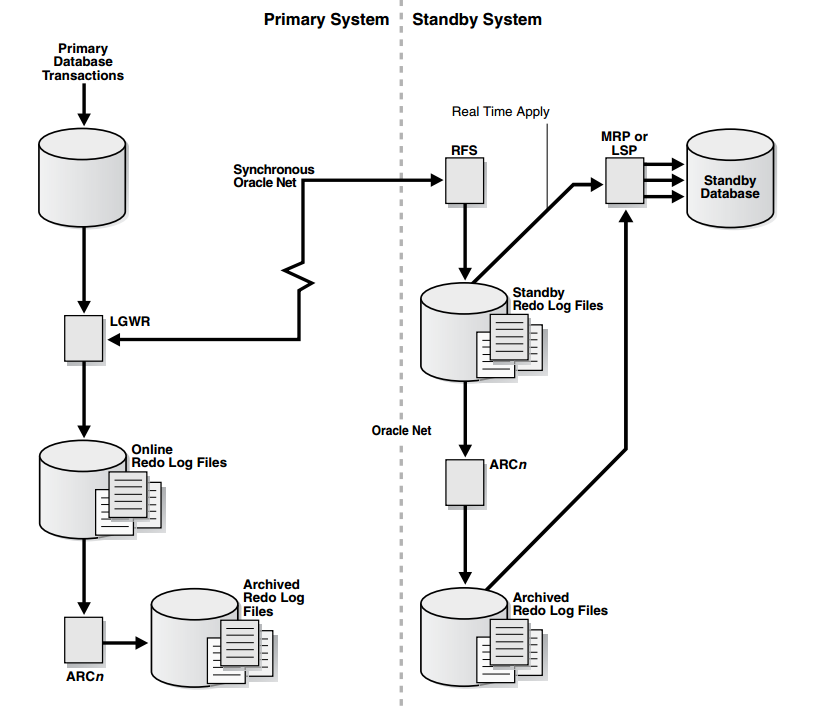
A arquitetura geral do Data Guard funciona da seguinte forma:
No momento em que ocorre um commit no Primary Database o LGWR se comunica com o RFS, que roda apenas no Standby Database, recebendo os dados de redo do Primary via Oracle Net, nisso o RFS (Remote File Server process) escreve nos standby redo logs que são aplicados pelo MRP (Managed Recovery Process) se for um Physical standby e estiver usando real time apply ou os comandos SQL são replicados pelo LSP (Logical Standby Process). Caso o real time apply não seja utilizado, então após o standby redo log file ser arquivado pelo processo ARCn o MRP ou LSP aplica os redos no Standby database através dos archives gerados pelo Standby.
Oracle Data Guard Services
São os serviços do Data Guard que, a grosso modo, “fazem ele funcionar”.
Apply Services
Aplica automaticamente os redo no standby database mantendo-o sincronizado com o primary database. Por default, o apply services espera pelo standby redo log file ser arquivado antes de aplicar os dados que esse redo possui. Entretanto, você pode habilitar o real-time apply que permite ao apply services aplicar o redo no current standby redo log que está sendo preenchido.
O Apply services usa dois métodos para manter o physical e o logical database sincronizados.
Redo Apply – Usado no physical database através de recover para manter o standby identicado ao primary.
SQL Apply – Usado somente no logical onde reconstrói os comandos SQL que estão no redo recebidos do primary e os executa no logical standby.
Redo Transport Services
Ele faz a transferência automática de redo log files entre os membros do Data Guard.
Cada destino de redo é individualmente configurado para receber dados de redo via um ou mais transport modes.
Synchronous: O Synchronous redo transport mode transmite os dados de redo simultanemanete respeitando o commit das transações. A transação não pode fazer o commit antes que os dados de redo gerados sejam enviados para todos os destinos do redo transport. Esse redo transport mode é usado pelos modos de proteção Maximum Protection e Maximum Availability.
Asynchronous: O asynchronous redo transport mode envia os dados de redo assincronamente para os destinos do redo transport sem respeitar o commit das transações. A transação pode efetuar o commit sem que os dados de redo sejam enviados para qualquer destino do redo transport que use o asynchronous redo transport mode.
Role Transitions: A role transition nada mais é do que mudar a role de um database do standby para primary ou de um primary para um standby usando um switchover ou failover. O switchover é quando você muda a database role de primary para standby e o standby vira o primary, essa mudança é uma mudança planejada, geralmente durante uma janela de manutenção. O failover é quando o primary cai por alguma razão (falta de luz, queda de rede, etc) e assim o failover acontece, o standby vira primary enquanto o primary fica indisponível.
A diferença entre um physical standby e o logical standby são a forma como eles aplicam os dados de redo. No physical o Data Guard usa o Redo Apply que aplica os dados de redo através de recover conforme a imagem abaixo:
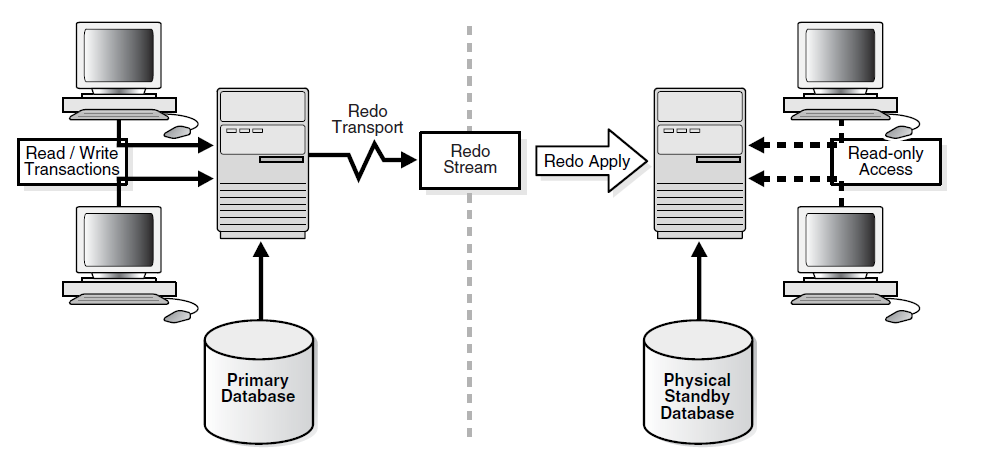
No logical standby database o Data Guard usa SQL Apply onde primeiro transforma os dados de redo em comandos SQL e depois os aplica no logical standby.

Oracle Data Guard Broker
O broker é um framework que automatiza a criação, manutenção e monitoração da configuração do Data Guard. Você pode usá-lo via Enterprise Manager Cloud Control (interface gráfico) ou via linha de comando pelo DGMGRL. Eles podem:
- Criar e habilitar as configurações do Data Guard incluindo configurar o redo transport services ou apply services.
- Gerenciar e monitorar o Data Guard inteiro em qualquer configuração, incluindo Oracle RAC ou Oracle RAC One Node.
- Simplifica switchovers e failovers.
- Habilita o Data Guard fast-start failover para automatizar o failover quando o primary database ficar indisponível. Quando o fast-start failover é habilitado o Broker determina se um failover é necessário e inicia o mesmo sem a necessidade de intervenção do DBA.
O Enterprise Manager Cloud Control ajuda nas tarefas:
- Criar um physical ou logical standby através de uma cópia do backup do primary.
- Adicionar um novo ou existente standby database a configuração do Data Guard
Modos de Proteção
O Data Guard é preparado para aderir a várias regras de negócio como por exemplo, ambientes que não podem sofrer nenhuma perda de dados, outros onde a disponibilidade é mais importante do que a perca de dados além de outros negócios onde a performance é o ponto mais crucial onde tolera a perda de dados ao invés da perda de performance.
Para isso, existem os modos de proteção:
Maximum Performance: É o modo de proteção default, se você não fizer nada ele será usado. Fornece o máximo de proteção de dados quanto possível sem a degradação da performance no primary database. Ele permite que as transações no primary sejam commitadas de forma assíncrona com o standby, em poucas palavras, ele não espera o standby fazer o commit para liberar a transação no primary.
Maximum Protection: Faz com que não exista nenhuma perca de dados do primary. Isso é tão levado a sério que se o primary estiver online e o standby, por algum motivo, ficar indisponível ou não for possível escrever os dados de redo nele o primary congela para evitar que nenhuma transação seja feita sem ser replicada para o standby. A garantia dessa proteção possui um preço, ele causa perca de performance no primary e é o mais lento dos três modos de proteção.
Maximum Availability: É a mescla dos modos de proteção Maximum Protection com o Maximum Performance. Ele atua como se fosse o Maximum Protection, se algo acontecer com o standby o primary atua como se fosse Maximum Performance fazendo com quem o primary nunca congele durante uma possível indisponibilidade ou falha temporária.
Dentro do Maximum Availability existem duas opções que fazem com que ele volte a usar o Maximum Performance.
- Dados de redo foram recebidos no standby e o I/O nos standby redo logs iniciou (mas ainda não terminou), enviando a mensagem que o primary pode continuar a transacionar. (SYNC/NOAFFIRM)
- Dados de redo foram recebidos e foram escritos nos standby redo logs, enviando a mensagem que o primary pode continuar a transacionar. (SYNC/AFFIRM)
Se o primary não receber a mensagem para continuar a transacionar de pelo menos um standby ele volta a usar o maximum performance.
As possibilidades são:
|
Maximum Availability |
Maximum Performance |
Maximum Protection |
|
AFFIRM or NOAFFIRM |
NOAFFIRM |
AFFIRM |
|
SYNC |
ASYNC |
SYNC |
Para alterar o modo de proteção use o comando:
ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE {AVAILABILITY | PERFORMANCE | PROTECTION};Você só pode setar o MAXIMUM PROTECTION com o database open se o protection mode atual for MAXIMUM AVAILABILITY e existir pelo menos um destino sincronizado com o database.
Para verificar o modo de proteção execute o select:
SQL> SELECT PROTECTION_MODE FROM V$DATABASETeste de comparação de cargas nos modos de proteção em 10.953.856 de linhas com os dados da tabela ALL_OBJECTS.
|
Modo de proteção |
Tempo |
|
DATA GUARD DESABILITADO |
04:48.55 |
|
MAXIMUM PERFORMANCE |
06:24.03 |
|
MAXIMUM AVAILABILITY |
10:55.37 |
|
MAXIMUM PROTECTION |
11:52.95 |
O Data Guard é uma ferramenta muito boa e deve ser usada o máximo de seus recursos quando adquiridos. Além de garantir uma alta disponibilidade ele também pode suprir necessidades de consumo de recursos. Por exemplo, você pode efetuar backups do Standby Database ao invés do Primary Database, isso economiza I/O e CPU do seu servidor de produção.
Pré Requisitos de Hardware e Sistema Operacional
Desde a versão 11g existe uma flexibilidade do Data Guard possuir ambientes heterogenêos como arquitetura de CPU, sistema operacional, binários do sistema operacional (32-bit/64-bit) ou binários do Oracle (32-bit/64-bit) diferentes.
Existem algumas restrições como você pode ver nas notas 413484.1 e 1085687.1.
Licenças Necessárias
Todos os membros da configuração do Data Guard devem ter a versão Enterprise Edition instaladas exceto durante rolling upgrades ou logical standbys momentâneos. Você pode usar o mesmo conceito do Data Guard em outras versões como Standard Edition fazendo a movimentação e recover dos archives manualmente (conhecido por ai como Data Pobre), mas não fornece a mesma facilidade que o Data Guard em si possui. Durante um rolling upgrade você pode usar o Logical Standby Database enquanto o seu Primary database ainda está em uma versão anterior (Primary 11g, Logical 12c, etc.)
Pré Requisitos Técnicos
O parâmetro COMPATIBLE deve ser igual para todos os database na configuração do Data Guard, menos o Logical que pode ter uma versão maior.
O standby databsae pode ser um single instance ou um Oracle RAC e esses standbys databases podem ser misturados entre physical, logical e snapshot databases.
Todos os databases devem ter o seu próprio control file.
Os destinos de archives devem ser diferentes para cada database ou eles irão se sobrescrever.
O FORCE LOGGING deve estar habilitado
Para gerenciar o Data Guard você precisa das permissões de SYSDBA ou SYSDG (introduzido no 12c).
Configurando Redo Transport Authentication
O Data Guard usa sessões do Oracle Net para transportar os dados de redos e controle de mensagens entre os membros configurados do Data Guard, o usuário default é o SYS, mas ele pode ser alterado para outro usuário.
O redo transport são autenticados pelo protocolo Secure Sockets Layer (SLL) ou pelo remote login password file. Caso você não use o SLL, toda vez que você alterar o arquivo de senhas do redo transport user e você estiver usando o remote login password file para autenticação você precisa copiar o password file mais recente para cada physical ou snapshot database que está configurado no Data Guard.
Entendendo os LOG_ARCHIVE_DEST_n e suas configurações
Veja o exemplo abaixo:
Primary database
ALTER SYSTEM SET LOG_ARCHIVE_DEST_1='LOCATION=/home/oracle/archives/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=ORCLP;
ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=ORCLSTB ASYNC NOAFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=ORCLSTB;Explicação:
LOG_ARCHIVE_DEST_1: sempre que você estiver na database role ALL_ROLES (todos os tipos de roles) você envia os ALL_LOGFILES (todos os tipos de redo log files) para o /home/oracle/archives/
LOG_ARCHIVE_DEST_2: sempre que você estiver na database role PRIMARY_ROLE (for produção) você envia os ONLINE_LOGFILES (online redo logs) para o service ORCLSTB (Standby). Aonde do ORCLSTB? Não sei, quem vai me dizer aonde eu devo enviar os redos é o próprio DB_UNIQUE_NAME ORCLSTB.
Standby Database
LOG_ARCHIVE_DEST_1=LOCATION=/home/oracle/archives_stby/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=ORCLSTB
LOG_ARCHIVE_DEST_2=SERVICE=ORCLP ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=ORCLP
O valor do LOG_ARCHIVE_DEST_1 do ORCLSTB é /home/oracle/archives_stby/ então sempre que ele for PRIMARY_ROLE ou STANDBY_ROLE ele vai enviar qualquer archive redo log para esse diretório e quando ele for PRIMARY_ROLE vai enviar os redo logs para o service ORCLP do DB_UNIQUE_NAME ORCLP, aonde? No valor configurado do LOG_ARCHIVE_DEST_1 do ORCLP.
Se você não usar o LOCATION, e sim o DB_RECOVERY_FILE_DEST o database usa o LOG_ARCHIVE_DEST_1 implicitamente.
Considerações
Cada database deve ter seu próprio control file (normal ou standby control file)
Não se esqueça de verificar o parâmetro COMPATIBLE que deve ser igual no primary e no standby.
FAL_SERVER (Fetch Archive Log)
O parâmetro FAL_SERVER especifica qual service name do Oracle Net será o responsável por eu pedir archives, no caso o meu standby (ORCLSTB) pede archives para o meu ORCLP
SQL> show parameter fal_server
NAME TYPE VALUE
------------------------------- ----------- -------
fal_server string ORCLPCascade Redo Transport
Um destino de redo transport cascade (também conhecido como terminal destination) recebe redo do primary indiretamente através do standby database ao invés de receber diretamente do primary database. Um physical standby database faz a cascata de redo do primary para um ou mais terminal destinations ao mesmo tempo. Você pode usar de 1 até 30 terminals destinations. Para poder usar o Data Guard Cascade você precisa usar a versão 11.2.0.2 ou superior.
A partir da versão 12.1 o cascading standby database pode fazer a cascata de redo em tempo real (está sendo escrito no standby redo log file) ou sem ser em tempo real. (standby redo logs são arquivados no cascading standby)
Existem algumas restrições:
- Somente o physical standby pode cascatear redo
- Real time cascading precisa de uma licença de Active Data Guard.
- O non-real-time cascading é suportado apenas para os destinos de 1 até 10, o real-time é suportado em todos. all destinations.)
Automatic Block Media Recovery
É possível efetuar a correção de blocos corrompidos em um dos databases, primary ou standby. Ele copia o bloco do outro database para o bloco corrompido.
Mas existem algumas condições para isso:
- É necessário o uso do Active Data Guard.
- Se não for possível reparar o bloco corrompido então ocorre o erro ORA-1578, caso contrário uma mensagem no alert log é gravada sobre a correção.
Oracle Active Data Guard
A Feature Active Data Guard habilita o Physical Standby, além de efetuar a proteção de dados, ser aberto para read-only. Isso possibilita gerar relatórios ou consultas muito pesadas em tempo real no Standby ao invés do Primary, evitando uma sobrecarga.
Gerenciando Standby Redo Logs
O synchronous e asynchronous redo transport mode precisa que os destinos do redo transport possuam standby redo logs. Um standby redo log é usado para armazenar redos recebidos de outro Oracle database. Standby redo logs são iguais aos redo logs (a.k online redo logs) e são criados e gerenciados usando os mesmos comandos que os online redo logs. Os online redo logs recebidos de outro database via redo transport são escritos no current standby redo log group pelo foreground process RFS (remote file server). Quando ocorre um log switch no grupo de redo do database de origem, os redos que chegam são escritos no standby redo log group seguinte e o standby redo log group anterior é arquivado (archived) pelo processo background ARCn. Esse processo de preenchimento sequencial e então arquivamento do redo log group no database de origem é espelhado para cada destino dos redo transports por preenchimento sequencial e arquivamento dos standby redo log groups. Cada standby redo log file deve ser pelo menos do mesmo tamanho ou maior que o online redo log group no database de origem, além de ter um ou mais grupos de redo que os grupos de redos de origem para cada thread. Sempre que um online redo log group for adicionado no primary um standby redo log group deve ser adicionado no standby database.
Casos onde o redo é escrito diretamente em um Archived Redo Log File.
Os redos recebidos pelo standby database são escritos diretamente em um archived log file se o standby redo log group não estiver disponível ou se o redo foi enviado para resolver um redo gap. Quando isso ocorre o redo é escrito para um local especificado no LOCATION de um dos LOG_ARCHIVE_DEST_n que é válido para arquivar (archiving) redo recebido de outro database. Para que o LOG_ARCHIVE_DEST_n seja reutilizado e marcado como ENABLED novamente basta alterar qualquer parâmetro nele.
Custo
O Oracle Data Guard já está incluso no preço do Enterprise Edition (EE), se você possui um, você já pode usá-lo. Lembrando que, é necessário um EE para o Primary e um EE para o Standby.
O que é adicional é a feature do Active Data Guard que possui um preço inicial de R$39,908.00 por processador e R$8,779.86 de suporte no primeiro ano.
Agora é só seguir o passo a passo do André e brincar.
Esperto ter ajudado, até logo!