

Coleta de estatísticas no Oracle – Parte II: Prática e opções de coleta
Olá pessoal, esse artigo é a segunda parte de uma série de artigos sobre coleta de estatísticas.
Sem rodeios, vamos ver como é a prática da coleta de estatísticas
SQL> create table t5 as select * from all_objects;
Table created.
SQL> select count(*) from all_objects;
COUNT(*)
----------
89780
SQL> select OWNER, TABLE_NAME, STATUS, NUM_ROWS, EMPTY_BLOCKS, AVG_SPACE, CHAIN_CNT, AVG_ROW_LEN,
TABLE_LOCK, SAMPLE_SIZE, LAST_ANALYZED, ROW_MOVEMENT, USER_STATS, GLOBAL_STATS from dba_tables
where TABLE_NAME='T5';
OWNER TABLE_NAME STATUS NUM_ROWS EMPTY_BLOCKS AVG_SPACE CHAIN_CNT AVG_ROW_LEN TABLE_LO SAMPLE_SIZE LAST_ANAL ROW_MOVEME USE GLO
---------- ---------- -------- ---------- ------------ ---------- ---------- ----------- -------- ----------- --------- ---------- --- ---
SYS VALID ENABLED DISABLED NO NO
SQL> begin
dbms_stats.gather_table_stats('SYS', 'T5');
end;
/
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, STATUS, NUM_ROWS, EMPTY_BLOCKS, AVG_SPACE, CHAIN_CNT, AVG_ROW_LEN,
TABLE_LOCK, SAMPLE_SIZE, LAST_ANALYZED, ROW_MOVEMENT, USER_STATS, GLOBAL_STATS from dba_tables
where TABLE_NAME='T5';
OWNER TABLE_NAME STATUS NUM_ROWS EMPTY_BLOCKS AVG_SPACE CHAIN_CNT AVG_ROW_LEN TABLE_LO SAMPLE_SIZE LAST_ANAL ROW_MOVEME USE GLO
---------- ---------- -------- ---------- ------------ ---------- ---------- ----------- -------- ----------- --------- ---------- --- ---
SYS VALID 89780 0 0 0 115 ENABLED 89780 14-MAR-16 DISABLED NO YESNo exemplo eu criei uma tabela com base na all_objects e verifique que não havia nenhuma informação de estatísticas nela, em seguida coletei estatísticas e verifique as informações da mesma. Por default só são necessários dois parâmetros para coletar estatísticas, o owner do objeto e o nome. O restante possui valores defaults que não são obrigatórios especifica-los. São eles:
ESTIMATE_PERCENT
Indica a quantidade de linhas de uma tabela que será coletada (em porcentagem), quanto maior for a quantidade de coletas mais preciso será o plano criado pelo CBO. Entretanto, a partir do 11g um novo algoritmo foi introduzido que é usado utilizando o AUTO_SAMPLE_SIZE onde ele, o próprio Oracle, decide a porcentagem que vai coletar. Se você não informar o valor do ESTIMATE_PERCENT ele usa o default (AUTO_SAMPLE_SIZE).
METHOD_OPT
Controla a criação de histogramas durante a coleta de estatísticas. O valor default é FOR ALL COLUMNS SIZE AUTO onde faz o Oracle automaticamente determinar quais colunas precisa de histogramas e os números de buckets que serão usados baseados nas informações da (DBMS_STATS.REPORT_COL_USAGE). As informações refletem a análise de todas as operações SQL que ocorreram para aquele objeto. Uma coluna é candidata a possuir histogramas se o valor da coluna foi usado na clausula WHERE como uma igualdade, um range, etc. O Oracle também verifica se os dados da coluna estão desordenados ou são distintos antes de criar um histograma. Se uma coluna possui várias linhas com um único valor não é criado um histograma.
Opções do METHOD_OPT
Algo muito importante sobre o METHOD_OPT são suas opções de coletas, pois é ele quem decide se será criado um histograma ou não, quais colunas terão estatísticas coletadas e a possibilidade estatísticas estendidas, além de nos possibilitar a criação manual de histogramas.
A sintaxe é dividida várias partes, onde apenas as duas primeiras são obrigatórias.
FOR ALL [INDEXED|HIDDEN] COLUMNS SIZE [SIZE_VALUE]
Primeira parte: Controla quais colunas terão suas estatísticas básicas coletadas (menor e maior valor, número de valores distintos, número de valores nulos, tamanho médio da linha, etc)
FOR ALL COLUMNS: É o valor default, faz a coleta de todas as estatísticas básicas para todas as colunas (isso inclui hidden columns).
FOR ALL INDEXED COLUMNS: Limita a coleta básica de estatísticas somente para aquelas colunas que possuem um índice.
FOR ALL HIDDEN COLUMNS: Limita a coleta básica de estatísticas somente a colunas virtuais que foram criadas nas tabelas. Só é usado quando uma nova coluna virtual é criada, ele coleta estatísticas das colunas virtuais, mas não das colunas normais.
Segunda parte: A segunda parte controla a criação de histogramas nas colunas.
AUTO: O Oracle decidirá automaticamente quais colunas precisam de histogramas baseado na tabela SYS.COL_USAGE$ e na presença de dados desordenados. Um valor inteiro significa que um histograma será criado (1 até 254), onde 1 significa que nenhum histograma será criado.
REPEAT: Certifica que um histograma será criado para somente para colunas que já possuam um histograma. Se a tabela é particionada, o repeat certifica que o histograma será criado para uma coluna que já exista a nível global. Entretanto, isso não é recomendado pois o número de buckets atuais serão limitados ao número de buckets criados no primeiro histograma. Se você tiver 10 buckets em uma coluna e efetuar a coleta com repeat e você precisar de 15 buckets, ele criará apenas 10.
SKEWONLY: Automaticamente cria histogramas em qualquer coluna que possua dados desordenados.
Criando histogramas em colunas específicas
Vamos assumir que queremos criar um histograma na coluna OWNER da minha tabela T.
SQL> desc T
Name Null? Type
----------------------------------------------------------------------------------------------------------------- -------- ----------------------------------------------------------------------------
OWNER NOT NULL VARCHAR2(128)
OBJECT_NAME NOT NULL VARCHAR2(128)
SUBOBJECT_NAME VARCHAR2(128)
OBJECT_ID NOT NULL NUMBER
DATA_OBJECT_ID NUMBER
OBJECT_TYPE VARCHAR2(23)
CREATED NOT NULL DATE
LAST_DDL_TIME NOT NULL DATE
TIMESTAMP VARCHAR2(19)
STATUS VARCHAR2(7)
TEMPORARY VARCHAR2(1)
GENERATED VARCHAR2(1)
SECONDARY VARCHAR2(1)
NAMESPACE NOT NULL NUMBER
EDITION_NAME VARCHAR2(128)
SHARING VARCHAR2(13)
EDITIONABLE VARCHAR2(1)
ORACLE_MAINTAINED VARCHAR2(1)
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T', method_opt => 'FOR ALL COLUMNS SIZE 1 FOR COLUMNS SIZE 254 OWNER');
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HIGH_VALUE, DENSITY, NUM_BUCKETS, LAST_ANALYZED,
HISTOGRAM
from dba_tab_col_statistics
where owner='GABRIEL' and TABLE_NAME='T' and COLUMN_NAME='OWNER';
OWNER TABLE_NAME COLUMN_NAM NUM_DISTINCT HIGH_VALUE DENSITY NUM_BUCKETS LAST_ANALYZED HISTOGRAM
---------- ---------- ---------- ------------ ---------- ------- ----------- ------------------- ---------------
GABRIEL T OWNER 30 584442 0 30 18-03-2016 10:43:51 FREQUENCYA primeira parte do comando diz para coletar estatísticas básicas em todas as colunas, por isso usamos o FOR ALL COLUMNS. Como queremos histogramas em uma única coluna utilizamos o SIZE 1 que indica a não criação de histogramas nas colunas onde as estatísticas básicas forem coletadas. Já o FOR COLUMNS SIZE 254 OWNER diz que eu quero um histograma nessa coluna, com o tamanho de até 254 buckets.
Para deletar o histograma, delete as estatísticas da coluna:
SQL> exec dbms_stats.delete_column_stats(ownname=>'GABRIEL', tabname=>'T', colname=>'OWNER');
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HIGH_VALUE, DENSITY, NUM_BUCKETS, LAST_ANALYZED, HISTOGRAM from dba_tab_col_statistics where owner='GABRIEL' and TABLE_NAME='T' and COLUMN_NAME='OWNER';DEGREE
Define o nível de paralelismo que o Oracle utilizará para efetuar a coleta. Por default o Oracle usa o mesmo número de parallel server processes atribuídos a tabela no dicionário de dados (Nível de paralelismo). O DEFAULT_DEGREE é calculado com PARALLEL_THREADS_PER_CPU x CPU_COUNT.
GRANULARITY
Define o nível de coleta que será efetuado em uma tabela particionada. Os níveis possíveis são partition (global) ou sub-partition. Por default o Oracle irá determinar qual o nível necessário baseado no tipo de partição da tabela.
CASCADE
Determina se a coleta será feita para índices da tabela ou não. Por default o AUTO_CASCADE faz com que o Oracle somente colete estatísticas para índices onde as estatísticas da tabela estão obsoletas. Depois que a coleta é feita, o índice é reconstruído e as estatísticas são automaticamente coletadas para ele fazendo com que não seja necessário coletar a estatísticas para o índice.
NO_INVALIDATE
Indica se os cursores que fazem referência a aquele objeto serão invalidados. Por exemplo, durante uma coleta de estatísticas do objeto uma query usa um plano efetuando FULL TABLE SCAN, após a coleta um novo plano será gerado usando INDEX RANGE SCAN. O NO_INVALIDATE faz com que os cursores sejam invalidados obrigando a efetuarem um novo parse e selecionando o novo plano com base nas estatísticas mais atuais. Por default ele não invalida os cursores.
ALTERANDO VALORES DEFAULT PARA OS PARAMETROS DA DBMS_STATS.GATHER_*_STATS
Você pode especificar um valor default conforme desejar para cada parâmetro da DBMS_STATS.GATHER_*_STATS individualmente ou sobrescrever o valor default para o database.
Isso é feito através da procedure DBMS_STATS.SET_*_PREFS, os parâmetros que podem ser alterados são: AUTOSTATS_TARGET (usado para o job de estatísticas da janela de manutenção), CONCURRENT (somente para SET_GLOBAL_PREFS), CASCADE, DEGREE, ESTIMATE_PERCENT, METHOD_OPT, NO_INVALIDATE, GRANULARITY, PUBLISH, INCREMENTAL e STALE_PERCENT.
Também pode ser setado um valor default para a coleta a nível de tabela, schema, database ou nível global usando a DBMS_STATS.SET_*_PREFS.
Tabela: SET_TABLE_PREFS, altera os valores dos parâmetros de coleta de apenas uma tabela. Mas ele não afeta nenhuma tabela nova criada após utilizar a SET_TABLE_PREFS. Novos objetos utilizaram as configurações globais (GLOBAL).
Schema: SET_SCHEMA_PREFS, altera os valores dos parâmetros de coleta para um schema e todas as suas tabelas.
Database: SET_DATABASE_PREFS, altera os valores dos parâmetros de coleta para todos os schemas e suas respectivas tabelas.
Tanto a SET_DATABASE_PREFS como a SET_SCHEMA_PREFS chama a SET_TABLE_PREFS durante sua execução. Todos os novos objetos usam os valores dos parâmetros com base na SET_GLOBAL_PREFS, menos parâmetros explícitos (informados na hora da execução) ou se existir um parâmetro default para uma determinada tabela. Além disso a SET_GLOBAL_PREFS permite o uso de dois parâmetros adicionais:
AUTOSTAT_TARGET: Controla quais objetos terão suas estatísticas coletadas pelo job da janela de manutenção, seus valores podem ser ALL, ORACLE e AUTO. O default é AUTO. Onde ALL significa para todos os objetos, ORACLE para apenas objetos internos do Oracle e AUTO para ele decidir o que precisa coletar ou não.
CONCURRENT: Controla se irá ou não coletar estatísticas em múltiplas tabelas em um schema, tabela, partições, sub partições ou database em paralelo. É um valor boolean e seu valor default é FALSE. Ele não impacta no job automático de coleta de estatísticas que roda na janela de manutenção. O Oracle sempre coleta um objeto de cada vez.
A hierarquia para definições de valores para os parâmetros são:
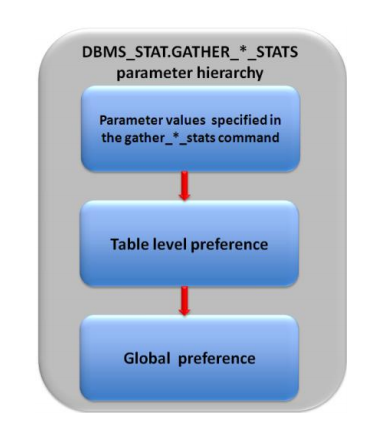
Primeiro é respeitado as definições que são passadas no próprio comando, se algum parâmetro não estiver sido usado explicitamente é usado o nível de preferência em tabelas, caso também não exista usa-se as preferenciais globais.
Para verificar um parâmetro para um objeto pode ser usado a function dbms_stats.get_prefs seguido pelo nome do parâmetro, schema e tabela:
select dbms_stats.get_prefs('STALE_PERCENT', 'SYS', 'T5') from dual;
DBMS_STATS.GET_PREFS('STALE_PERCENT','SYS','T5')
-------------------------------------------------------------------------------------------
10
SQL> begin
2 dbms_stats.set_table_prefs('SYS', 'T5','STALE_PERCENT', '65');
3 end;
4 /
PL/SQL procedure successfully completed.
SQL> select dbms_stats.get_prefs('STALE_PERCENT', 'SYS', 'T5') from dual;
DBMS_STATS.GET_PREFS('STALE_PERCENT','SYS','T5')
-------------------------------------------------------------------------
65
gather_database_stats_job_procJOB AUTOMÁTICO DE COLETA DE ESTATÍSTICAS
O Oracle coleta estatísticas automaticamente de objetos do database que não possuem estatísticas ou que possuem estatísticas obsoletas no job que ocorre durante a janela de manutenção.
A janela ocorre durante a semana entre 22h00 e 02h00 e entre 06h00 até 02h00 aos finais de semana. A Task da janela de manutenção executa a procedure DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC que opera de uma forma similar a DBMS_STATS.GATHER_DATABASE_STATS usando a opção GATHER AUTO, a grande diferença é que o Oracle prioriza os objetos que mais precisam de estatísticas. A estatísticas das tabelas são consideradas obsoletas quando as linhas alteradas são maiores que o STALE_PERCENT (valor default de 10%), o Oracle monitora todos os DML ocorridos na SGA e imputa essas informações na DBA_TAB_MODIFICATIONS:
SQL> select TABLE_OWNER, TABLE_NAME, INSERTS, UPDATES, DELETES, TIMESTAMP from DBA_TAB_MODIFICATIONS where TABLE_OWNER <> 'SYS';
TABLE_OWNE TABLE_NAME INSERTS UPDATES DELETES TIMESTAMP
---------- ------------------------------ ---------- ---------- ---------- ---------
DBSNMP BSLN_TIMEGROUPS 0 0 0 24-JAN-16
EODA BIN$LXVFxqk4Ct7gU3g4qMDqaw==$0 0 0 40 07-MAR-16
AUDSYS CLI_SWP$105f844b$1$1 3 0 0 10-MAR-16É possível efetuar o flash da SGA para a view manualmente com a DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO (o flush ocorre automaticamente antes de toda coleta de estatísticas). Também é possível ver se existem estatísticas obsoletas na coluna STALE_STATS da DBA_TAB_STATISTICS onde NO significa que as estatísticas estão atualizadas, YES estão obsoletas e quando vazia é que nunca foram coletadas.
Para ver o histórico das coletas de todas as estatísticas, manual ou via job, use o select abaixo:
SQL> select OPERATION, TARGET, START_TIME, END_TIME, STATUS, JOB_NAME from DBA_OPTSTAT_OPERATIONS ;
OPERATION TARGET START_TIME END_TIME STATUS JOB_NAME
------------------------------ -------------------- ----------------------------------- ----------------------------------- ---------- ---------------------------
gather_database_stats (auto) AUTO 28-FEB-16 09.03.30.267615 AM -03:00 28-FEB-16 09.04.41.021895 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_161
purge_stats 28-FEB-16 09.04.41.022211 AM -03:00 28-FEB-16 09.04.41.396842 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_161
purge_stats 28-FEB-16 09.04.41.397056 AM -03:00 28-FEB-16 09.04.41.871230 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_161
gather_table_stats SYS.T5 14-MAR-16 09.36.58.110560 AM -03:00 14-MAR-16 09.37.01.942305 AM -03:00 COMPLETED
gather_table_stats SYS.AUD$ 22-FEB-16 04.30.58.386567 PM -03:00 22-FEB-16 04.30.59.058941 PM -03:00 COMPLETED
gather_table_stats SYS.FGA_LOG$ 22-FEB-16 04.32.31.285252 PM -03:00 22-FEB-16 04.32.31.751287 PM -03:00 COMPLETED
gather_table_stats SYS.AUD$ 22-FEB-16 04.34.09.899513 PM -03:00 22-FEB-16 04.34.10.297622 PM -03:00 COMPLETED
gather_table_stats SYS.FGA_LOG$ 22-FEB-16 04.34.10.477934 PM -03:00 22-FEB-16 04.34.10.701758 PM -03:00 COMPLETED
gather_table_stats SYS.AUD$ 22-FEB-16 04.34.47.203916 PM -03:00 22-FEB-16 04.34.47.439824 PM -03:00 COMPLETED
gather_table_stats SYS.FGA_LOG$ 22-FEB-16 04.34.47.460064 PM -03:00 22-FEB-16 04.34.47.508919 PM -03:00 COMPLETED
gather_table_stats EODA.BIG_TABLE 07-MAR-16 08.40.28.023554 AM -03:00 07-MAR-16 08.40.28.740909 AM -03:00 COMPLETED
gather_database_stats (auto) AUTO 15-MAR-16 08.26.05.467204 AM -03:00 15-MAR-16 08.29.29.516544 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_181
purge_stats 15-MAR-16 08.29.29.553545 AM -03:00 15-MAR-16 08.29.33.247276 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_181
purge_stats 15-MAR-16 08.29.33.247905 AM -03:00 15-MAR-16 08.29.35.123435 AM -03:00 COMPLETED ORA$AT_OS_OPT_SY_181
Essa view possui uma coluna chamada NOTES onde, aparentemente, mostra as opções usadas.
SQL> select NOTES from DBA_OPTSTAT_OPERATIONS where TARGET ='AUTO';
NOTES
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
<params><param name="block_sample" val="FALSE"/><param name="cascade" val="NULL"/><param name="concurrent" val="FALSE"/><param name="degree" val="DEFAULT_DEGREE_VALUE"/><param name="estimate_percent"
val="DEFAULT_ESTIMATE_PERCENT"/><param name="granularity" val="DEFAULT_GRANULARITY"/><param name="method_opt" val="DEFAULT_METHOD_OPT"/><param name="no_invalidate" val="DBMS_STATS.AUTO_INVALIDATE"/><p
aram name="reporting_mode" val="FALSE"/><param name="stattype" val="DATA"/></params>
<params><param name="block_sample" val="FALSE"/><param name="cascade" val="NULL"/><param name="concurrent" val="FALSE"/><param name="degree" val="DEFAULT_DEGREE_VALUE"/><param name="estimate_percent"
val="DEFAULT_ESTIMATE_PERCENT"/><param name="granularity" val="DEFAULT_GRANULARITY"/><param name="method_opt" val="DEFAULT_METHOD_OPT"/><param name="no_invalidate" val="DBMS_STATS.AUTO_INVALIDATE"/><p
aram name="reporting_mode" val="FALSE"/><param name="stattype" val="DATA"/></params>Eu ACREDITO (não encontrei nada na documentação que diga isso), que essa seja a forma como o job automático coleta as estatísticas no seu job da janela de manutenção. Na versão 11.2.0.2 o modo de coleta concurrent foi introduzido com o objetivo de criar múltiplos processos de coleta para cada sub partition e partition em uma tabela. A quantidade de jobs que serão executadas e a quantidade deles que serão enfileirados é baseada no número de job queue processes (JOB_QUEUE_PROCESSES) e recursos disponíveis no servidor/database. Isso faz com que eles sejam executados em paralelo. Se a coleta usar a DBMS_STATS.GATHER_DATABASE_STATS, DBMS_STATS.GATHER_SCHEMA_STATS ou DBMS_STATS.GATHER_DICTIONARY_STATS o Oracle cria um job separado para cada coleta de uma tabela não particionada. Cada tabela particionada terá um job coordinator que gerencia os jobs dessas partições e sub partições. O database executará o máximo de jobs possíveis e enfileirará outros jobs enquanto esses não forem concluídos. Entretanto, para prevenir possíveis deadlocks várias tabelas particionadas não podem ser processadas simultaneamente.
A figura abaixo mostra a criação de jobs em níveis diferentes usando a DBMS_STATS.GATHER_SCHEMA_STATS no schema SH. O Oracle cria um job para cada tabela não particionada (nível 1) e o job coordinator de cada tabela particionada, SALES e COSTS, cria um job de coleta para cada partição (nível 2):
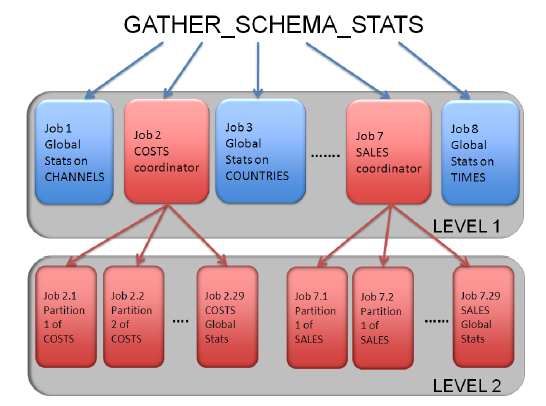
Vamos assumir que o parâmetro JOB_QUEUE_PROCESSES esteja em 32, o Oracle Job Scheduler irá permitir 32 jobs de coleta de estatísticas sejam iniciados e irá enfileirar o resto. Supondo que os primeiros 29 jobs (um para cada partição mais o job coordinator) para a tabela COSTS foi iniciado e então três tabelas não particionadas também iniciem. O job para a tabela SALES será automaticamente enfileirado porque somente uma tabela particionada é processada por vez. Assim que um job finalizar, outro job sairá da fila e será iniciado até todos jobs sejam concluídos.
Para alterar as configurações do concurrent mode utilize:
BEGIN
DBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','TRUE');
END;
/Para não executar os processos em paralelo utilize o JOB_QUEUE_PROCESSES para 2 x o total de número de CPU cores.
COLETANDO ESTATÍSTICAS EM TABELAS PARTICIONADAS
Coletar estatísticas de tabelas particionadas consiste em coletar ambos os níveis, de tabela e de partição. Antes da versão 11g adicionar uma nova partição ou modificar dados em uma partição precisava ler a tabela inteira para atualizar as estatísticas a nível de tabela. Se você pulasse a coleta a nível global o Optimizer iria explorar a nível global com base no nível de partições. Algumas informações poderiam ser coletadas dessa forma, outras como o número de valores distintos em uma coluna (crucial para o Optimizer) não era possível. Na versão 11g foi introduzido as estatísticas globais incrementais (incremental global statistics). Se o parâmetro INCREMENTAL para uma tabela particionada é setada como TRUE, o GRANULARITY inclui GLOBAL e o ESTIMATE_PERCENT está como AUTO_SAMPLE_SIZE na DBMS_STATS.GATHER_*_STATS o Oracle irá coletar nas novas partições e atualizará as estatísticas a nível global lendo apenas as partições que foram adicionadas ou modificadas e não a tabela inteira.
A incremental global statistics trabalha armazenado uma sinopse (resumo) para cada partição em uma tabela. As sinopses são metadados estáticos para cada partição e suas colunas, cada sinopse é armazenada na tablespace SYSAUX. Quando adicionado uma nova partição em uma tabela, só é necessário coletar estatísticas para aquela partição e não para a tabela toda.
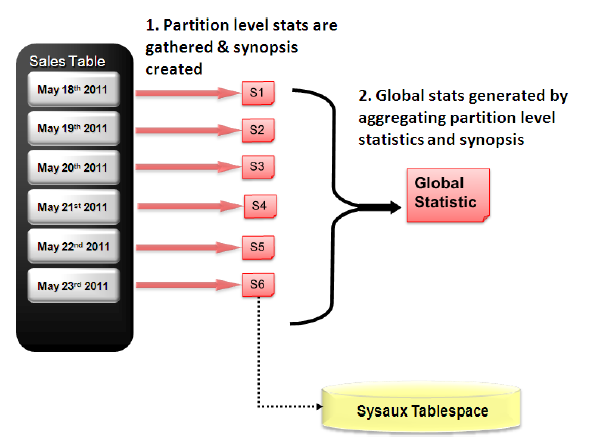
Para criar estatísticas incrementais a nível de tabela ou a nível global:
BEGIN
DBMS_STATS.SET_TABLE_PREFS('SH','SALES','INCREMENTAL','TRUE');
END;
/Para verificar a configuração:
SELECT DBMS_STATS.GET_PREFS('INCREMENTAL','SH','SALES') FROM dual;Note que o INCREMENTAL não será aplicado para a sub-partitions. As estatísticas serão coletadas normalmente nas sub-partitions e partition. Somente as estatísticas de partições serão usadas para determinar as estatísticas de nível global ou a nível de tabela.
Gerenciando estatísticas
A Oracle oferece diversas opções para gerenciar a coleta de estatísticas, é possível restaurar, movimentar estatísticas de um sistema para outro e, até mesmo, setar valores manualmente.
Restaurando estatísticas
Desde a versão 10g em diante, quando você coleta estatísticas com a DBMS_STATS, as estatísticas originais são automaticamente mantidas nas tabelas do dicionário do banco de dados e podem ser restauradas usando a DBMS_STATS.RESTORE_TABLE_STATS.
A view do dicionário de dados DBA_TAB_STATS_HISTORY contém uma lista de datas de quando foram coletas estatísticas das tabelas.
BEGIN
DBMS_STATS.RESTORE_TABLE_STATS(ownname => 'SH',
tabname => 'SALES',
as_of_timestamp => SYSTIMESTAMP-1
force => FALSE,
no_invalidate => FALSE);
END;
/No exemplo acima foi restaurado as estatísticas da tabela SALES do schema SH de ontem com a opção de invalidar todos os cursores que o utilizem.
As estatísticas antigas (consideradas antigas após a nova coleta) são automaticamente deletadas baseados na retenção de 31 dias, o que quer dizer que você poderá restaurar as estatísticas a qualquer momento, desde que tenham a data menor que 31 dias. O purge automático já é habilitado com o STATISTICS_LEVEL é TYPICAL ou ALL, se você desabilitar o purge automático então terá que deletar manualmente.
O select abaixo mostra as estatísticas que ainda existem para as tabelas:
select owner, TABLE_NAME, STATS_UPDATE_TIME from DBA_TAB_STATS_HISTORY;
OWNER TABLE_NAME STATS_UPDATE_TIME
-------- ---------- ----------------------------------------
GABRIEL PEDIDO 16-MAR-16 08.04.34.129665 AM -03:00
GABRIEL PEDIDO 16-MAR-16 08.04.34.129665 AM -03:00
GABRIEL PEDIDO 16-MAR-16 08.04.34.129665 AM -03:00
GABRIEL PEDIDO 16-MAR-16 08.05.52.668840 AM -03:00
GABRIEL PEDIDO 16-MAR-16 08.13.41.074292 AM -03:00
Para verificar o período de retenção atual use o select abaixo:
SQL> select dbms_stats.get_stats_history_retention from dual;
GET_STATS_HISTORY_RETENTION
---------------------------
31Para alterar use o alterar o valor use a function abaixo:
SQL> exec dbms_stats.alter_stats_history_retention(7);
PL/SQL procedure successfully completed.
SQL> select dbms_stats.get_stats_history_retention from dual;
GET_STATS_HISTORY_RETENTION
---------------------------
7Para coletar o valor de estatística mais antigo possível em um restore use o select abaixo:
SQL> select dbms_stats.get_stats_history_availability from dual;
GET_STATS_HISTORY_AVAILABILITY
---------------------------------------------------------------------------
15-FEB-16 08.09.54.928926000 AM -03:00Se eu precisasse, eu poderia restaurar qualquer estatística desde 15/02/2016 às 09h54.
Estatísticas Pendentes
Por defaul quando você coleta estatísticas elas são automaticamente publicadas (escritas) imediatamente nas tabelas do dicionário de dados para serem utilizadas pelo Optimizer. Na versão 11g para frente é possível coletar as estatísticas, mas não publicá-las imediatamente. Elas podem ser habilitadas apenas para sessões individuais, ambientes de testes por exemplo, antes de serem publicadas. Para alterar a configuração default do parâmetro PUBLISH que é TRUE para FALSE fazendo com que as estatísticas não sejam publicadas por default.
BEGIN
DBMS_STATS.SET_TABLE_PREFS('SYS','T5','PUBLISH','FALSE');
END;
/Após alterar basta coletar as estatísticas normalmente:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS('SYS','T5');
END;
/Você pode ver as estatísticas pendentes, veja a view DBA_TAB_PENDING_STATS:
SQL> select OWNER, TABLE_NAME, NUM_ROWS, SAMPLE_SIZE, LAST_ANALYZED from DBA_TAB_PENDING_STATS;
OWNER TABLE_NAME NUM_ROWS SAMPLE_SIZE LAST_ANAL
---------- ------------------------------ ---------- ----------- ---------
SYS T5 89780 89780 15-MAR-16Em seguida, basta publica-la:
BEGIN
DBMS_STATS.PUBLISH_PENDING_STATS('SYS','T5');
END;
/Se você executar a query na DBA_TAB_PENDING_STATS novamente não haverá nenhuma estatística pendente.
SQL> select OWNER, TABLE_NAME, NUM_ROWS, SAMPLE_SIZE, LAST_ANALYZED from DBA_TAB_PENDING_STATS;
no rows selectedExportando/Importando Estatísticas
Existe a possibilidade de exportar ou importar estatísticas em um database. Isso é feito quando você deseja simular que o Optimizer do seu ambiente de teste/homologação/qualidade trabalhe como o Optimizer de produção.
Você pode efetuar esse procedimento usando as procedures DBMS_STATS.EXPORT_*_STATS e DBMS_STATS.IMPORT_*_STATS, mas antes de exportar as estatísticas você precisa criar uma tabela para armazenar os dados com a procedure DBMS_STATS.CREATE_STAT_TABLE.
Veja o exemplo abaixo:
SQL> CREATE OR REPLACE DIRECTORY EXPORT_STATS as '/home/oracle/export_stats';
Directory created.
SQL> BEGIN
dbms_stats.create_stat_table('DBAORACLE', 'TAB_ESTATISTICAS');
END;
/
PL/SQL procedure successfully completed.Vou coletar estatísticas do meu schema para deixar o mais atual possível:
SQL> begin
dbms_stats.gather_schema_stats('GABRIEL');
end;
/
PL/SQL procedure successfully completed.
-- Exporto as estatísticas do schema para a tabela de estatísticas criada
SQL> EXEC DBMS_STATS.export_schema_stats('GABRIEL','TAB_ESTATISTICAS',NULL,'DBAORACLE');
PL/SQL procedure successfully completed.
SQL> select count(*) from dbaoracle.tab_estatisticas;
COUNT(*)
----------
29
[oracle@liverpool export_stats orcl12c]$expdp '/ as sysdba ' tables=dbaoracle.tab_estatisticas directory=EXPORT_STATS dumpfile=expdp_gabriel_tab_stats.dmp logfile=expdp_gabriel_tab_stats.log
Export: Release 12.1.0.2.0 - Production on Tue Mar 15 16:38:01 2016
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
Starting "SYS"."SYS_EXPORT_TABLE_01": "/******** AS SYSDBA" tables=dbaoracle.tab_estatisticas directory=EXPORT_STATS dumpfile=expdp_gabriel_tab_stats.dmp logfile=expdp_gabriel_tab_stats.log
Estimate in progress using BLOCKS method...
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
Total estimation using BLOCKS method: 192 KB
Processing object type TABLE_EXPORT/TABLE/TABLE
Processing object type TABLE_EXPORT/TABLE/INDEX/INDEX
Processing object type TABLE_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type TABLE_EXPORT/TABLE/STATISTICS/MARKER
. . exported "DBAORACLE"."TAB_ESTATISTICAS" 20.14 KB 29 rows
Master table "SYS"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded
******************************************************************************
Dump file set for SYS.SYS_EXPORT_TABLE_01 is:
/home/oracle/export_stats/expdp_gabriel_tab_stats.dmp
Job "SYS"."SYS_EXPORT_TABLE_01" successfully completed at Tue Mar 15 16:38:31 2016 elapsed 0 00:00:29
Agora, por uma questão prática, vou dropar a tabela de estatísticas que criei e deletar as estatísticas do schema GABRIEL. Assim, seria a simulação de importar as estatísticas em outro database.
SQL> EXEC DBMS_STATS.delete_schema_stats('GABRIEL');
PL/SQL procedure successfully completed.
SQL> select max(LAST_ANALYZED) from dba_tab_statistics where OWNER='GABRIEL';
MAX(LAST_
---------
SQL> drop table dbaoracle.tab_estatisticas;
Table dropped.
[oracle@liverpool export_stats orcl12c]$impdp '/ as sysdba ' tables=dbaoracle.tab_estatisticas directory=EXPORT_STATS dumpfile=expdp_gabriel_tab_stats.dmp logfile=impdp_gabriel_tab_stats.log
Import: Release 12.1.0.2.0 - Production on Tue Mar 15 16:43:07 2016
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
Master table "SYS"."SYS_IMPORT_TABLE_01" successfully loaded/unloaded
Starting "SYS"."SYS_IMPORT_TABLE_01": "/******** AS SYSDBA" tables=dbaoracle.tab_estatisticas directory=EXPORT_STATS dumpfile=expdp_gabriel_tab_stats.dmp logfile=impdp_gabriel_tab_stats.log
Processing object type TABLE_EXPORT/TABLE/TABLE
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
. . imported "DBAORACLE"."TAB_ESTATISTICAS" 20.14 KB 29 rows
Processing object type TABLE_EXPORT/TABLE/INDEX/INDEX
Processing object type TABLE_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type TABLE_EXPORT/TABLE/STATISTICS/MARKER
Job "SYS"."SYS_IMPORT_TABLE_01" successfully completed at Tue Mar 15 16:43:22 2016 elapsed 0 00:00:14
Verifico o import da tabela:
SQL> select count(*) from dbaoracle.tab_estatisticas;
COUNT(*)
----------
29Mas isso não quer dizer que as estatísticas foram populadas no schema:
select max(LAST_ANALYZED) from dba_tab_statistics where OWNER='GABRIEL';
MAX(LAST_
---------Precisamos importa-las:
SQL> EXEC DBMS_STATS.import_schema_stats('GABRIEL','TAB_ESTATISTICAS',NULL,'DBAORACLE');
PL/SQL procedure successfully completed.
Agora sim:
SQL> select max(LAST_ANALYZED) from dba_tab_statistics where OWNER='GABRIEL';
MAX(LAST_
---------
15-MAR-16Copiando Estatísticas de Partições
O Optimizer utiliza dois tipos de estatísticas quando estamos usando tabelas particionadas, as estatísticas globais e as estatísticas para cada partição. Se a query precisa acessar somente uma única partição o Optimizer usa apenas as estatísticas daquela partição, se a query acessar dados em mais de uma partição ele usa a combinação de estatísticas globais e das partições acessadas. É bem comum uma tabela com range partition ter um novo range criado e ter linhas inseridas somente naquele novo range. Se um usuário iniciar uma query inserindo dados antes das estatísticas serem coletadas, é possível que ele use um suboptimal execution plan para lidar com as estatísticas obsoletas. Um caso comum é quando o valor utilizado na clausula where é de dois ranges diferentes representados pelo valor mínimo e máximo nas estatísticas das partições. Isso é conhecido como “out of range”, onde o Optimizer divide a seletividade baseado na distância entre o valor da clausula where e do valor máximo da partição, ou seja, quanto mais “longe” é o valor do valor mínimo ou valor máximo da partição, menor será a seletividade.
Esse “out of range” pode ser prevenido através da DBMS_STATS.COPY_TABLE_STATS que copia estatísticas representativas de uma partition ou sub partition para popular a nova partição ou sub partição.
– Se a partição é do tipo HASH o menor e maior valor da partição destino são os mesmos que na partição de origem.
– Se a partição é do tipo LIST e a partição destino é uma partição NOT DEFAULT então o menor valor da partição de destino é setado para o menor valor do valor da lista que descreve a partição de destino, o valor máximo da partição de destino é setado para o valor máximo da partição de origem.
– Se a partição é do tipo LIST e a partição de destino é do uma partição DEFAUL então o menor valor da partição de destino é setado para o menor valor de origem, o maior valor da partição de destino é setado para o maior valor da partição de origem.
– Se a partição é do tipo RANGE então o menor valor da partição de destino é setado para o mais alto valor da partição anterior e o valor máximo da partição de destino é setado para o mais alto valor da própria partição de destino a não ser que o mais alto valor da partição de destino seja o MAXVALUE.
CREATE TABLE pedido
(id_ped NUMBER NOT NULL,
date_ped DATE NOT NULL
)
PARTITION BY RANGE (date_ped)
(PARTITION par_12_2015_ped VALUES LESS THAN (TO_DATE('31/12/2015', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION par_01_2016_ped VALUES LESS THAN (TO_DATE('31/01/2016', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION par_02_2016_ped VALUES LESS THAN (TO_DATE('29/02/2016', 'DD/MM/YYYY')) TABLESPACE users,
PARTITION par_03_2016_ped VALUES LESS THAN (TO_DATE('31/03/2016', 'DD/MM/YYYY')) TABLESPACE users);
insert into gabriel.pedido partition (par_12_2015_ped) values (1, '01/12/2015');
insert into gabriel.pedido partition (par_12_2015_ped) values (2, '02/12/2015');
insert into gabriel.pedido partition (par_12_2015_ped) values (3, '03/12/2015');
insert into gabriel.pedido partition (par_12_2015_ped) values (13, '01/12/2015');
insert into gabriel.pedido partition (par_12_2015_ped) values (14, '02/12/2015');
insert into gabriel.pedido partition (par_12_2015_ped) values (15, '03/12/2015');
insert into gabriel.pedido partition (par_01_2016_ped) values (4, '01/01/2016');
insert into gabriel.pedido partition (par_01_2016_ped) values (5, '02/01/2016');
insert into gabriel.pedido partition (par_01_2016_ped) values (6, '03/01/2016');
insert into gabriel.pedido partition (par_01_2016_ped) values (16, '01/01/2016');
insert into gabriel.pedido partition (par_01_2016_ped) values (17, '02/01/2016');
insert into gabriel.pedido partition (par_01_2016_ped) values (18, '03/01/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (7, '01/02/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (8, '02/02/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (9, '03/02/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (19, '01/02/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (20, '02/02/2016');
insert into gabriel.pedido partition (par_02_2016_ped) values (21, '03/02/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (10, '01/03/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (11, '02/03/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (12, '03/03/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (22, '01/03/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (23, '02/03/2016');
insert into gabriel.pedido partition (par_03_2016_ped) values (24, '03/03/2016');
commit;
select OWNER, TABLE_NAME, PARTITION_NAME, PARTITION_POSITION, NUM_ROWS, AVG_ROW_LEN, LAST_ANALYZED,
GLOBAL_STATS
from dba_tab_statistics
where TABLE_NAME='PEDIDO';
SQL> exec dbms_stats.gather_table_stats('GABRIEL','PEDIDO', CASCADE => TRUE);
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, PARTITION_NAME, PARTITION_POSITION, NUM_ROWS, AVG_ROW_LEN, LAST_ANALYZED,
GLOBAL_STATS
from dba_tab_statistics
where TABLE_NAME='PEDIDO';
OWNER TABLE_NAME PARTITION_NAME PARTITION_POSITION NUM_ROWS AVG_ROW_LEN LAST_ANAL GLO
-------- ---------- -------------------- ------------------ ---------- ----------- --------- ---
GABRIEL PEDIDO 20 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_12_2015_PED 1 3 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_01_2016_PED 2 6 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_02_2016_PED 3 8 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_03_2016_PED 4 3 11 16-MAR-16 YESEstatísticas de índices são somente copiados se os nomes dos índices particionados forem os mesmos das partições da tabela (comportamento default). O único momento em que as estatísticas globais serão impactadas pela procedure DBMS_STATS.COPY_TABLE_STATS seria se não existissem estatísticas globais.
SQL> exec dbms_stats.lock_partition_stats('GABRIEL', 'PEDIDO', 'PAR_03_2016_PED');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.delete_table_stats('GABRIEL', 'PEDIDO');
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, PARTITION_NAME, PARTITION_POSITION, NUM_ROWS, AVG_ROW_LEN, LAST_ANALYZED,
GLOBAL_STATS
from dba_tab_statistics
where TABLE_NAME='PEDIDO';
OWNER TABLE_NAME PARTITION_NAME PARTITION_POSITION NUM_ROWS AVG_ROW_LEN LAST_ANAL GLO
-------- ------------------------------ ------------------------------ ------------------ ---------- ----------- --------- ---
GABRIEL PEDIDO NO
GABRIEL PEDIDO PAR_12_2015_PED 1 NO
GABRIEL PEDIDO PAR_01_2016_PED 2 NO
GABRIEL PEDIDO PAR_02_2016_PED 3 NO
GABRIEL PEDIDO PAR_03_2016_PED 4 3 11 16-MAR-16 YES
SQL> exec DBMS_STATS.COPY_TABLE_STATS('GABRIEL','PEDIDO','PAR_03_2016_PED','PAR_01_2016_PED', 2);
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, PARTITION_NAME, PARTITION_POSITION, NUM_ROWS, AVG_ROW_LEN, LAST_ANALYZED,
GLOBAL_STATS
from dba_tab_statistics
where TABLE_NAME='PEDIDO';
OWNER TABLE_NAME PARTITION_NAME PARTITION_POSITION NUM_ROWS AVG_ROW_LEN LAST_ANAL GLO
-------- ------------------------------ ------------------------------ ------------------ ---------- ----------- --------- ---
GABRIEL PEDIDO NO
GABRIEL PEDIDO PAR_12_2015_PED 1 NO
GABRIEL PEDIDO PAR_01_2016_PED 2 6 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_02_2016_PED 3 NO
GABRIEL PEDIDO PAR_03_2016_PED 4 3 11 16-MAR-16 YESComparando Estatísticas
Uma das grandes razões que um plano de execução pode diferir de um ambiente para outro é porque as estatísticas do Optimizer são diferentes entre eles (o famoso cenário PROD x HOM).
Para identificar as diferenças nas estatísticas é possível usar as funções DBMS_STATS.DIFF_TABLE_STATS_* podendo comparar estatísticas de duas tabelas de origens diferentes.
As estatísticas de origem podem ser:
– As estatísticas de uma tabela de um usuário e as estatísticas no dicionário de dados.
– As estatísticas de uma tabela de um usuário com dois conjuntos de estatísticas diferentes (statids diferentes).
– As estatísticas de duas tabelas diferentes de um usuário.
– Dois pontos no tempo.
– As estatísticas atuais e um momento na história.
– Estatísticas pendentes e as estatísticas atuais no dicionário de dados.
– Estatísticas pendentes com as estatísticas na tabela de um usuário.
A função também compara estatísticas de objetos dependentes (índices colunas e partições) e mostra todas as estatísticas para aquele objeto para as duas origens e se as diferenças excederam um threshold. Esse threshold pode ser especificado no argumento da função onde o valor default é 10%. As estatísticas correspondem para a primeira origem e será usada como base para computação base para a diferenciação delas.
SQL> select table_name,stats_update_time
from dba_tab_stats_history
where owner='GABRIEL' and TABLE_NAME='T';
TABLE_NAM STATS_UPDATE_TIME
--------- ---------------------------------------------------------------------------
T 28-FEB-16 09.04.25.786157 AM -03:00
T 16-MAR-16 08.35.20.464321 AM -03:00
select * from table(dbms_stats.diff_table_stats_in_history(
ownname => 'GABRIEL',
tabname => upper('T'),
time1 => systimestamp,
time2 => to_timestamp('28-02-2016 09:04:25 ','dd-mm-yyyy hh24:mi:ss'),
pctthreshold => 0));
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
############################################################################### 100
STATISTICS DIFFERENCE REPORT FOR:
.................................
TABLE : T
OWNER : GABRIEL
SOURCE A : Statistics as of 16-MAR-16 09.05.55.197297 AM -03:00
SOURCE B : Statistics as of 28-FEB-16 09.04.25.000000 AM -03:00
PCTTHRESHOLD : 0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
TABLE / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS BLOCKS ROWLEN SAMPSIZE
...............................................................................
T T A 626368 11149 115 626368
B 89269 1534 116 89269
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
COLUMN STATISTICS DIFFERENCE:
.............................
COLUMN_NAME SRC NDV DENSITY HIST NULLS LEN MIN MAX SAMPSIZ
...............................................................................
CREATED A 1028 .000972762 NO 0 8 78720 78740 626368
B 955 .001047120 NO 0 8 78720 78740 89269
DATA_OBJECT_ID A 6367 .000157059 NO 582796 2 80 C30A1 43572
B 5984 .000167112 NO 83248 2 80 C30A1 6021
EDITIONABLE A 2 .5 NO 274567 2 4E 59 351801
B 2 .5 NO 39016 2 4E 59 50253
EDITION_NAME A 0 0 NO 626368 0 NULL
B 0 0 NO 89269 0 0
LAST_DDL_TIME A 1156 .000865051 NO 0 8 78660 78740 626368
B 1059 .000944287 NO 0 8 78660 78740 89269
OBJECT_ID A 89676 .000011151 NO 0 5 C103 C30A1 626368
B 89269 .000011202 NO 0 5 C103 C30A1 89269
OBJECT_NAME A 51840 .000019290 NO 0 25 2F313 79436 626368
B 51524 .000019408 NO 0 25 2F313 79436 89269
OWNER A 28 .035714285 NO 0 6 41504 58444 626368
B 26 .038461538 NO 0 6 41504 58444 89269
STATUS A 2 .5 NO 0 7 494E5 56414 626368
B 1 1 NO 0 6 56414 56414 89269
SUBOBJECT_NAME A 474 .002109704 NO 620835 2 24565 57524 5533
B 305 .003278688 NO 88670 2 24565 57524 599
TIMESTAMP A 1190 .000840336 NO 0 20 31393 32303 626368
B 1094 .000914076 NO 0 20 31393 32303 89269
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
INDEX / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS LEAFBLK DISTKEY LF/KY DB/KY CLF LVL SAMPSIZ
...............................................................................
INDEX: IDX_T_OWNER
..................
IDX_T_OWNER I A 626368 1861 28 66 704 19717 2 626368
B 178538 418 26 16 216 5632 1 178538
###############################################################################</pre>
Para comparar as estatísticas atuais com estatísticas pendentes:
SQL> EXEC DBMS_STATS.set_param('PUBLISH', 'FALSE');
PL/SQL procedure successfully completed.
SQL> insert into gabriel.t select * from all_objects;
90016 rows created.
SQL> /
90016 rows created.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T');
PL/SQL procedure successfully completed.
SQL> select * from table(DBMS_STATS.DIFF_TABLE_STATS_IN_PENDING(ownname => 'GABRIEL', tabname =>'T', time_stamp => NULL, pctthreshold =>1));
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
###############################################################################
STATISTICS DIFFERENCE REPORT FOR:
.................................
TABLE : T
OWNER : GABRIEL
SOURCE A : Current Statistics in dictionary
SOURCE B : Pending Statistics
PCTTHRESHOLD : 1
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
TABLE / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS BLOCKS ROWLEN SAMPSIZE
...............................................................................
T T A 626368 11149 115 626368
B 806400 14209 115 806400
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
COLUMN STATISTICS DIFFERENCE:
.............................
COLUMN_NAME SRC NDV DENSITY HIST NULLS LEN MIN MAX SAMPSIZ
...............................................................................
CREATED A 1028 .000972762 NO 0 8 78720 78740 626368
B 1082 .000924214 NO 0 8 78720 78740 806400
DATA_OBJECT_ID A 6367 .000157059 NO 582796 2 80 C30A1 43572
B 6665 .000150037 NO 749620 2 80 C30A2 56780
EDITIONABLE A 2 .5 NO 274567 2 4E 59 351801
B 2 .5 NO 353933 2 4E 59 452467
EDITION_NAME A 0 0 NO 626368 0 NULL
B 0 0 NO 806400 0 0
LAST_DDL_TIME A 1156 .000865051 NO 0 8 78660 78740 626368
B 1232 .000811688 NO 0 8 78660 78740 806400
NAMESPACE A 16 .0625 NO 0 3 C102 C141 626368
B 22 .045454545 NO 0 3 C102 C15E 806400
OBJECT_ID A 90912 .000010999 NO 0 5 C103 C30A1 626368
B 91336 NULL NO 0 5 C103 C30A2 806400
OBJECT_TYPE A 38 .000000798 YES 0 9 434C5 584D4 626368
B 44 .000000620 YES 0 9 434C5 584D4 806400
OWNER A 28 .035714285 NO 0 6 41504 58444 626368
B 30 .033333333 NO 0 6 41504 58444 806400
SUBOBJECT_NAME A 474 .002109704 NO 620835 2 24565 57524 5533
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
B 515 .001941747 NO 799035 2 24565 57524 7365
TIMESTAMP A 1190 .000840336 NO 0 20 31393 32303 626368
B 1264 .000791139 NO 0 20 31393 32303 806400
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
INDEX / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS LEAFBLK DISTKEY LF/KY DB/KY CLF LVL SAMPSIZ
...............................................................................
INDEX: IDX_T_OWNER
..................
IDX_T_OWNER I A 626368 1861 28 66 704 19717 2 626368
B 806400 2432 30 81 846 25395 NUL 806400
INDEX: IDX_OBJ_ID
.................
IDX_OBJ_ID I A 626368 1387 90912 1 6 626368 2 626368
B 806400 2774 90126 1 8 806400 NUL 806400
###############################################################################Para comparar as estatísticas de duas tabelas:
SQL> create table t2 as select * from t where rownum < 1001;
Table created.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T2', ESTIMATE_PERCENT =>1);
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.create_stat_table('GABRIEL', 'TAB_ESTATISTICAS_T2');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.create_stat_table('GABRIEL', 'TAB_ESTATISTICAS_T');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.export_table_stats(ownname => 'GABRIEL', stattab=> 'TAB_ESTATISTICAS_T', tabname=>'T');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.export_table_stats(ownname => 'GABRIEL', stattab=> 'TAB_ESTATISTICAS_T2', tabname=>'T2');
PL/SQL procedure successfully completed.
SQL> select * from table(DBMS_STATS.DIFF_TABLE_STATS_IN_STATTAB('GABRIEL','T','TAB_ESTATISTICAS_T','TAB_ESTATISTICAS_T2'));
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
###############################################################################
STATISTICS DIFFERENCE REPORT FOR:
.................................
TABLE : T
OWNER : GABRIEL
SOURCE A : User statistics table TAB_ESTATISTICAS_T
: Statid :
: Owner : GABRIEL
SOURCE B : User statistics table TAB_ESTATISTICAS_T2
: Statid :
: Owner : GABRIEL
PCTTHRESHOLD : 10
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
TABLE / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS BLOCKS ROWLEN SAMPSIZE
...............................................................................
T T A 806400 14209 115 806400
B NO_STATS
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
COLUMN STATISTICS DIFFERENCE:
.............................
COLUMN_NAME SRC NDV DENSITY HIST NULLS LEN MIN MAX SAMPSIZ
...............................................................................
CREATED A 1082 .000924214 NO 0 8 78720 78740 806400
B NO_STATS
DATA_OBJECT_ID A 6665 .000150037 NO 749620 2 80 C30A2 56780
B NO_STATS
EDITIONABLE A 2 .5 NO 353933 2 4E 59 452467
B NO_STATS
EDITION_NAME A 0 0 NO 806400 0 NULL
B NO_STATS
GENERATED A 2 .5 NO 0 2 4E 59 806400
B NO_STATS
LAST_DDL_TIME A 1232 .000811688 NO 0 8 78660 78740 806400
B NO_STATS
NAMESPACE A 22 .045454545 NO 0 3 C102 C15E 806400
B NO_STATS
OBJECT_ID A 91336 .000010948 NO 0 5 C103 C30A2 806400
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
B NO_STATS
OBJECT_NAME A 51904 .000019266 NO 0 25 2F313 79436 806400
B NO_STATS
OBJECT_TYPE A 44 .000000620 YES 0 9 434C5 584D4 806400
B NO_STATS
ORACLE_MAINTAIN A 2 .5 NO 0 2 4E 59 806400
B NO_STATS
OWNER A 30 .033333333 NO 0 6 41504 58444 806400
B NO_STATS
SECONDARY A 1 1 NO 0 2 4E 4E 806400
B NO_STATS
SHARING A 3 .333333333 NO 0 14 4D455 4F424 806400
B NO_STATS
STATUS A 2 .5 NO 0 7 494E5 56414 806400
B NO_STATS
SUBOBJECT_NAME A 515 .001941747 NO 799035 2 24565 57524 7365
B NO_STATS
TEMPORARY A 2 .5 NO 0 2 4E 59 806400
B NO_STATS
TIMESTAMP A 1264 .000791139 NO 0 20 31393 32303 806400
B NO_STATS
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
INDEX / (SUB)PARTITION STATISTICS DIFFERENCE:
.............................................
OBJECTNAME TYP SRC ROWS LEAFBLK DISTKEY LF/KY DB/KY CLF LVL SAMPSIZ
...............................................................................
INDEX: IDX_T_OWNER
..................
IDX_T_OWNER I A 806400 2432 30 81 846 25395 2 806400
B NO_STATS
INDEX: IDX_OBJ_ID
.................
IDX_OBJ_ID I A 806400 2774 91336 1 8 806400 2 806400
B NO_STATS###############################################################################
TRAVANDO ESTATÍSTICAS (LOCKING STATISTICS)
Em alguns casos pode ser necessário travar as estatísticas de uma tabela ou schema, uma vez travada nenhuma modificação pode ser feita nessas estatísticas até que elas sejam destravadas ou use o FORCE=TRUE na procedure GATHER_*_STATS.
SQL> create table t as select * from all_objects;
Table created.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.lock_table_stats('GABRIEL', 'T');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T');
BEGIN dbms_stats.gather_table_stats('GABRIEL', 'T'); END;
*
ERROR at line 1:
ORA-20005: object statistics are locked (stattype = ALL)
ORA-06512: at "SYS.DBMS_STATS", line 34634
ORA-06512: at line 1
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'T', FORCE=>TRUE);
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.unlock_table_stats('GABRIEL', 'T');
PL/SQL procedure successfully completed.Desde a versão 11g a package DBMS_STATS foi expandida para permitir que as estatísticas de partições sejam travadas e destravadas.
SQL> EXEC DBMS_STATS.LOCK_PARTITION_STATS('GABRIEL','PEDIDO', 'PAR_02_2016_PED');
PL/SQL procedure successfully completed.Existe uma hierarquia no “travamento” das estatísticas. Por exemplo, se você trava as estatísticas em uma tabela particionada e destravou as estatísticas em uma única partição para coletar estatísticas você receberá o erro ORA-20005, pois as estatísticas a nível de tabela ainda estão travadas. Só ocorreria a coleta na partição específica se você usar o FORCE=TRUE.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'PEDIDO');
PL/SQL procedure successfully completed.
SQL> select OWNER, TABLE_NAME, PARTITION_NAME, PARTITION_POSITION, NUM_ROWS, AVG_ROW_LEN, LAST_ANALYZED,
GLOBAL_STATS, STATTYPE_LOCKED
from dba_tab_statistics
where TABLE_NAME='PEDIDO';
OWNER TABLE_NAM PARTITION_NAME PARTITION_POSITION NUM_ROWS AVG_ROW_LEN LAST_ANAL GLO STATT
------- --------- -------------------- ------------------ ---------- ----------- --------- --- -----
GABRIEL PEDIDO 20 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_12_2015_PED 1 3 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_01_2016_PED 2 6 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_02_2016_PED 3 8 11 16-MAR-16 YES
GABRIEL PEDIDO PAR_03_2016_PED 4 3 11 16-MAR-16 YES
SQL> exec dbms_stats.lock_table_stats('GABRIEL', 'PEDIDO');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.unlock_partition_stats('GABRIEL','PEDIDO','PAR_03_2016_PED');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'PEDIDO', 'PAR_02_2016_PED');
BEGIN dbms_stats.gather_table_stats('GABRIEL', 'PEDIDO', 'PAR_02_2016_PED'); END;
*
ERROR at line 1:
ORA-20005: object statistics are locked (stattype = ALL)
ORA-06512: at "SYS.DBMS_STATS", line 34634
ORA-06512: at line 1
SQL> exec dbms_stats.gather_table_stats('GABRIEL', 'PEDIDO', 'PAR_02_2016_PED', FORCE => TRUE);
PL/SQL procedure successfully completed.Imputando Manualmente as Estatísticas
Também é possível setar os valores de estatísticas para uma tabela manualmente com a procedure DBMS_STATS.SET_*_STATS, mas não é muito recomendado, você não é mais esperto que o Optimizer, acredite. Um exemplo para isso seria uma tabela temporária global.
Quando coletar estatísticas?
Essa é uma pergunta que dá muita cerveja na mesa de bar e muitos DBA’s discutem sobre o tema. O que a Oracle diz sobre isso:
“When gathering statistics manually, you not only need to determine how to gather statistics, but also when and how often to gather new statistics.
For tables that are substantially modified in batch operations, such as with bulk loads, gather statistics on these tables as part of the batch operation. Call the DBMS_STATS procedure as soon as the load operation completes.
Sometimes only a single partition is modified. In such cases, you can gather statistics only on the modified partitions rather than on the entire table. However, gathering global statistics for the partitioned table may still be necessary.”
Alguns DBA’s gostam de coletar quando ocorrem 10%, 5%, 3%, etc, de alterações em um determinado objeto. A verdade é que não existe uma receita de bolo, colete X% que você estará ok. Acredito que você deve analisar o negócio do cliente, como ele funciona e decidir sua estratégia. Por exemplo: Imagine uma tabela de 50.000.000 de linhas que sofre constante alteração (transações de cartão de crédito). Para essa tabela chegar em 10% de alterações seriam necessário 5 milhões de transações, o que gera uma discrepância enorme na hora de criar um plano de execução. Agora imagine uma tabela com 100 linhas, para chegar a 10% de alterações, não são necessárias mais que 10 transações nessa tabela. E é aí que regra do negócio interfere e deve ser levada em consideração. Se a tabela tiver 50 milhões de linhas, mas sofrer 1.000 transações por dia a coleta deve ser feita de X em X tempo, se a tabela tiver 100 linhas, mas sofrer 10 milhões de transações por dia (Obs: transação não é INSERT e DELETE apenas, não esqueça do UPDATE), tabela de FRETE por exemplo, a coleta deve ser feita de Y em Y tempo.
Dynamic Sampling
Outra informação de estatísticas de estatísticas vem das estatísticas de sistemas e do dynamic sampling. O dynamic sampling foi introduzido na versão 9iR2 para coletar informações adicionais de objetos específicos através das estatísticas durante a otimização do comando SQL.Um grande equívoco é pensar que o dynamic sampling pode ser usado para substituir as estatísticas do Optimizer.
O objetivo do dynamic sampling é acrescentar estatísticas as estatísticas já existentes ou ausentes. É usado quando as estatísticas atuais não são suficientes para uma boa estimativa de cardinalidade. Então, quando e como o dynamic sampling será usado? Durante a compilação do comando SQL, o Optimizer decide se utilizará ou não considerando se as estatísticas atuais são suficientes para gerar um plano de execução bom. Se as estatísticas não forem suficientes o dynamic sampling será usado. Ele é usado para compensar a ausência ou estatísticas ruins que poderiam ser usados para um plano de execução. Por exemplo, se uma ou mais tabelas não possuírem estatísticas o dynamic plan faz a coleta para o Optimizer ter pelo menos as informações básicas. Porém, as estatísticas não são tão eficientes quanto as coletadas na DBMS_STATS pois se fossem as mesmas o overhead utilizado para gerar um plano seria muito grande.
Outro cenário que fará o dynamic sampling ser utilizado é quando um comando contém expressões complexas na clausula where e as estatísticas estendidas não estão disponíveis.
SQL> exec dbms_stats.delete_schema_stats('GABRIEL');
PL/SQL procedure successfully completed.
SQL> select OWNER, OBJECT_NAME from t where OBJECT_ID > 345 and OBJECT_TYPE <> 'TABLE';
608314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 556K| 83M| 3027 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 556K| 83M| 3027 (1)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID">345 AND "OBJECT_TYPE"<>'TABLE')
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
57937 consistent gets
10609 physical reads
0 redo size
27161588 bytes sent via SQL*Net to client
446645 bytes received via SQL*Net from client
40556 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
608314 rows processed
SQL> exec dbms_stats.gather_schema_stats('GABRIEL', CASCADE =>TRUE);
PL/SQL procedure successfully completed.
SQL> select OWNER, OBJECT_NAME from t where OBJECT_ID > 345 and OBJECT_TYPE <> 'TABLE';
608314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 607K| 26M| 3028 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 607K| 26M| 3028 (1)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_TYPE"<>'TABLE' AND "OBJECT_ID">345)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
50494 consistent gets
10609 physical reads
0 redo size
27161588 bytes sent via SQL*Net to client
446645 bytes received via SQL*Net from client
40556 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
608314 rows processed
O level 2 no dynamic sample informado no campo “Notes” é baseado no parâmetro OPTIMIZER_DYNAMIC_SAMPLING
SQL> show parameter OPTIMIZER_DYNAMIC_SAMPLING
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 2O valor do OPTIMIZER_DYNAMIC_SAMPLING vai de 0 (desabilitado) até 10.
Abaixo estão as diferenças para cada valor:
|
Level |
Quando será usado |
Tamanho da amostra (em blocos) |
|
0 |
Desabilitado. |
N/A |
|
1 |
Quando houver no mínimo uma tabela não particionada sem estatísticas. |
32 |
|
2 |
Quando houver uma ou mais tabelas sem estatísticas (default). |
64 |
|
3 |
Quando o critério for o mesmo do level 2 ou um comando que tenha uma ou mais expressões nos valores da clausula WHERE. Ex Where col1 + col2 |
64 |
|
4 |
Quando o critério for o mesmo do level 3 ou valores que possuam operadores OR e AND na mesma tabela. |
64 |
|
5 |
Quando o critério for o mesmo que o level 4. |
125 |
|
6 |
Quando o critério for o mesmo que o level 4. |
256 |
|
7 |
Quando o critério for o mesmo que o level 4. |
512 |
|
8 |
Quando o critério for o mesmo que o level 4. |
1024 |
|
9 |
Quando o critério for o mesmo que o level 4. |
4086 |
|
10 |
Todos os comandos. |
Todos os blocos |
O dynamic sample não será usado em tabelas remotas (Via Database Link e External Tables) para isso ele utiliza alguns valores default:


Estatísticas de sistema (System Statistics)
As estatísticas de sistema foram apresentadas no Oracle 9i com o intuito de fazer o Optimizer ser mais preciso em relação ao custo na hora da execução de um plano através das informações de hardware do sistema atual como velocidade de CPU e I/O.
Elas são habilitadas por default e são automaticamente iniciadas com valores default (são valores representativos para cada sistema operacional). Quando você coleta manualmente as estatísticas de sistema pela primeira vez, os novos valores serão sobrescritos. Mas como eu sei se já foram coletadas estatísticas de sistema no meu ambiente? Quando eu devo coletá-las?
SQL> desc SYS.AUX_STATS$
Name Null? Type
----------------------------------------- -------- ----------------------------
SNAME NOT NULL VARCHAR2(30)
PNAME NOT NULL VARCHAR2(30)
PVAL1 NUMBER
PVAL2 VARCHAR2(255)
A SYS.AUX_STATS$ possui quatro colunas com cerca de 13 linhas:
SQL> select * from sys.aux_stats$;
SNAME PNAME PVAL1 PVAL2
--------------- --------------- ---------- -----------------
SYSSTATS_INFO STATUS COMPLETED
SYSSTATS_INFO DSTART 07-07-2014 06:53
SYSSTATS_INFO DSTOP 07-07-2014 06:53
SYSSTATS_INFO FLAGS 1
SYSSTATS_MAIN CPUSPEEDNW 3308.9701
SYSSTATS_MAIN IOSEEKTIM 10
SYSSTATS_MAIN IOTFRSPEED 4096
SYSSTATS_MAIN SREADTIM
SYSSTATS_MAIN MREADTIM
SYSSTATS_MAIN CPUSPEED
SYSSTATS_MAIN MBRC
SNAME PNAME PVAL1 PVAL2
--------------- --------------- ---------- -----------------
SYSSTATS_MAIN MAXTHR
SYSSTATS_MAIN SLAVETHRCada valor para PNAME significa um indicador, são eles:
STATUS
Se a estatísticas de sistema está sendo executada ou foi concluída.
DSTART
Data do início da coleta.
DSTOP
Data do fim da coleta.
CPUSPEEDNW
Representa a velocidade da CPU sem nenhuma carga. A velocidade da CPU é apresentada na média do número de ciclos de CPU por segundo, sua unidade de medida é milhões por segundo. Seu valor default é definido durante o startup da instancia.
IOSEEKTIM
Representa o tempo de solicitação de I/O onde o cálculo é feito como: tempo de espera de I/O + tempo de latência + tempo de resposta do sistema operacional. Seu valor default é 10, sua unidade de medida é em milisegundos.
IOTFRSPEED
Velocidade da transferência de I/O onde ele representa a taxa que o Oracle consegue ler em uma única requisição. O valor default é 4096 e sua unidade de medida é em bytes por milisegundos.
CPUSPEED
Representa a velocidade da CPU durante uma carga, assim como o CPUSPEEDNW ela é definida pela média do número de ciclos de CPU por segundo. Não possui valor default, mas sua unidade de medida é em milhões por segundo.
MAXTHR
Representa o máximo de throughput que o sistema pode entregar (input e output). Não possui valor default, mas sua unidade de medida é em bytes por segundos.
SLAVETHR
Representa a média do throughput de I/O para um processo em paralelo. Não possui valor default, mas sua unidade de medida é em bytes por segundo.
SREADTIM
Representa o tempo médio de leitura de um único bloco aleatoriamente. Não possui valor default, mas sua unidade de medida é em milisegundos.
MREADTIM
Representa o tempo médio de leitura de vários blocos sequencialmente. Não possui valor default, mas sua unidade de medida é em milisegundos.
MBRC
Representa a contagem média de leitura de vários blocos sequencialmente. Não possui valor default, mas sua unidade de medida é em blocos.
Os valores SYSSTATS_INFO, SYSSTATS_MAIN e SYSSTATS_TEMP (não está no exemplo) significam:
SYSSTATS_INFO: Informações do estado do sistema.
SYSSTATS_MAIN: Informações do conteúdo do sistema.
SYSSTATS_TEMP: Informações de coleta de estatísticas do sistema usadas durante intervalos de tempo.
Noworkload x Workload
Durante a coleta de Workload statistics são coletadas as seguintes informações:
Single and multiblock read times, mbrc, cpuspeed, throughput máximo do sistema e o average slave throughput. O Oracle computa o sreadtim, mreadtim e o mbrc comparando o número de leituras físicas sequenciais com leituras aleatórias entre dois pontos no tempo entre o começo e o fim da workload. Esses valores são inseridos por meio de contadores que mudam quando a buffer cache completa uma leitura síncrona de requisições. Pelo o fato dos contadores estarem na buffer cache eles não incluem somente atrasos no I/O, mas também waits relacionados a contenção de latches e tarefas de switch.
As Workload statistics dependem da atividade do sistema durante uma janela de coleta. Se o sistema estava no seu limite de I/O durante a coleta, então as estatísticas irão refletir essa situação e promover um plano de execução com menor intensidade de I/O para o database.
Durante a coleta das Noworkload statistics são coletadas as seguintes informações:
Velocidade de transferência de I/O, velocidade de CPU e tempo de solicitação de I/O. A grande diferença entre a workload e a noworkload está no método de coleta.
A coleta por noworkload statistics submete leituras aleatórias em todos os data files enquanto a workload statistics usa contadores para atualizar quando a atividade do database ocorre. O ioseektim representa o tempo que demora para posicionar o ponteiro do header do disco até a leitura dos dados. Esse valor varia de 5 até 15 milissegundos dependendo da velocidade rotação do disco e do tipo de RAID.
A velocidade de transferência de I/O representa a velocidade que o sistema operacional pode ler dados no disco onde esse valor varia de alguns até milhares de mbs por segundo.
Se existirem workload statistics o oracle ignora o noworkload statistics e usa as workloads.
Para coletar as workload statistics use os comandos
— Para iniciar
execute dbms_stats.gather_system_stats(‘start’);
— Para finalizer
execute dbms_stats.gather_system_stats(‘stop’);
— Para coletar durante intervalos
execute dbms_stats.gather_system_stats(‘interval’, interval=>n)
Onde N é medido em minutos
— Para coletar noworkload statistics use o comando
exec dbms_stats.gather_system_stats();
— Para deletar as estatísticas use o comando
exec dbms_stats.delete_system_stats();
Você pode setar os valores manualmente para todos os valores caso você deseje (não se esqueça que você não é mais inteligente que o Optimizer).
exec dbms_stats.set_system_stats(‘iotfrspeed’, 4096);
Influências no Multiblock Read Count
Se você coletar as workload statistics então o mbrc será usado para estimar o custo de um full table scan. Entretanto, durante o processo de coleta da workload statistics, o Oracle pode não coletar os valores do mbrc e mreadtim se não ocorrerem full table scans durante a workload seriais, algo muito comum em ambientes OLTP. Entretanto, full table scans ocorrem frequentemente em ambientes DSS, mas muitas vezes em paralelo evitando a buffer cache. Se o Oracle não coletar as informações do mbrc ou do mreadtim, mas coletar os valores para o sreadtim e do cpuspeed então ele utilizará apenas esses valores para calcular o custo, assim o Optimizer usa o valor do DB_FILE_MULTIBLOCK_READ_COUNT para calcular o custo de um full table scan, se ele estiver sem nenhum valor ou igual a 0 então o Optimizer usa o valor 8 para o cálculo.
Quando coletar system stats?
Como o sistema (hardware) é algo que não muda sempre (não adicionamos memória, CPU, trocamos os discos todos os dias) as coletas devem ser feitas durante a primeira vez e quando ocorrem mudanças significativas, ou seja, quando houver uma mudança de hardware no ambiente. Vale lembrar que também deve ser considera fazer uma manutenção na coleta das estatísticas, isto é, sabemos que o hardware se torna obsoleto, o disco vai perdendo sua potência com o passar do tempo, necessitando a troca do mesmo, etc. Isso interfere diretamente no I/O e no database. Use sempre a workload statistics quando for coletar e o período de coleta deve ser um dia normal do seu ambiente, o dia normal significa um dia em que não ocorre uma carga no ambiente (fechamento mensal, processamento de relatórios, etc.) durante o seu horário comercial, a razão disso é que se você coletar as estatísticas de sistema durante uma carga o Optimizer sempre criará planos de execução com base no I/O máximo de disco, o que pode não ser uma verdade naquele momento. E você não deve coletar as estatísticas de sistema quando o database estiver ocioso pois também não vai refletir seu processamento comum.
Estatísticas das tabelas do Dicionário de dados (Dictionary Tables)
As tabelas do dicionário de dados (tabelas do SYS, SYSTEM, etc que residem nas tablespaces SYSAUX e SYS) também precisam ter suas estatísticas coletadas.
Essa coleta é feita automaticamente no job da janela de manutenção, mas você pode desabilitar se desejar. É recomendado que você colete as estatísticas do dicionário de dados da mesma forma que coleta as estatísticas do usuário.
Estatísticas em Objetos Fixos (Fixed Objects)
O Oracle também precisa de estatísticas nas tabelas que constituem as v$, são elas as x$. O dynamic sampling não é automaticamente usado nessas tabelas para ajudar o Optimizer gerando planos ruins. Para isso o Optimizer utiliza valores defaults pré-definidos quando esses valores não são encontrados. Quando isso ocorrer podemos ter problemas de performance, por essa razão sempre é necessário coletar essas estatísticas.
A DBMS_STATS.GATHER_FIXED_OBJECTS_STATS coleta as mesmas informações que a DBMS_STATS.GATHER_TABLE_STATS porém, o número de blocos é sempre 0 porque as x$ estão em memória, nunca armazenadas em disco.
Você deve coletar novamente essas estatísticas quando houver um upgrade no database ou na sua aplicação.
— Para coletar use o comando:
exec DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
Conclusão
Podemos chegar ao consenso que as estatísticas são extremamente importantes para o Oracle, podendo causar grandes impactos na performance quando ausentes. Além disso também é importante saber se estão,como estão equais estão sendo coletadas (tabelas, índices, sistema, fixed objetos, etc.)
No próximo artigo vou abordar as melhores práticas sobre estatísticas segundo a Oracle, espero ter ajudado, até logo!
Se você não leu o artigo anterior, é só clicar no link abaixo: