

Result Cache em Functions: O reaproveitamento de resultados no Oracle
Quem gosta de fazer algo que já fez outrora e que já sabe o resultado? Eu não. E acredito que o banco de dados Oracle sempre esteve incomodado em repetir uma ação que ele já sabe o retorno. Até por isso, na versão 11 release 1 foi disponibilizado o RESULT_CACHE que permite – no popular – o reaproveitamento do resultado de uma execução anterior. É claro que no Oracle já existem – há muito tempo – outros mecanismos de cache, mas aqui temos algumas particularidades.
A keyword RESULT_CACHE informa aos dados “se guarde, que vou lhe usar”. Os resultados permanecem em cache e podem ser utilizados por outras sessões, não somente na corrente. Desta maneira, ao ser executado uma FUNCTION, com os mesmos argumentos e parâmetros, o resultado estará em cache e esta informação é que será retornada sem a necessidade de execuções extras.
Ainda, imagine que sua FUNCTION busca informações de uma tabela e esta tabela sofra alguma modificação nos dados. Neste caso não se preocupe, pois o cache será invalidado e as novas informações serão captadas novamente e colocada em cache. Isto acontece de forma transparente apenas para o Oracle 11g a partir do Release 2. Entretanto, no Release 1 você deverá, para estas situações, se antever e adicionar RELIES_ON(tabela) após RESULT_CACHE, caso o retorno de sua FUNCTION dependa de uma tabela.
Vamos aos exemplos:
Antes de tudo deverá ser verificado se o RESULT_CACHE está ativo:
SELECT dbms_result_cache.status() FROM dual;
Caso seja retornado DISABLE, deverá ser habilitado, conforme abaixo. Para este caso deverá ter privilégio de DBA:
ALTER SYSTEM SET RESULT_CACHE_MAX_SIZE = 3M SCOPE = BOTH;
ALTER SYSTEM SET RESULT_CACHE_MAX_RESULT = 5 SCOPE = BOTH;Promover o Shutdown e Startup do banco, e verificar se as alterações surtiram efeitos:
SELECT dbms_result_cache.status() FROM dual;
Vamos criar a tabela base que utilizaremos na FUNCTION exemplo.
CREATE TABLE temp_teste AS
(SELECT ROWNUM my_id,
Substr(dbms_random.String('U', 10), 1, 10) my_name,
Round(dbms_random.Value(1, 7000)) salary
FROM dual
CONNECT BY LEVEL <= 100 -- quantidade de registro a serem criados
)Para criar a FUNCTION exemplo, utilize o script abaixo:
CREATE OR replace FUNCTION F_buscaf(v_myid IN temp_teste.my_id%TYPE)
RETURN temp_teste%ROWTYPE
IS
v_return temp_teste%ROWTYPE;
BEGIN
SELECT my_id,
my_name,
salary
INTO v_return.my_id, v_return.my_name, v_return.salary
FROM temp_teste
WHERE my_id = 1;
dbms_output.Put_line('RODOU');
RETURN v_return;
END f_buscaf;Observe que foi colocado um PUT_LINE com a palavra “RODOU” dentro da FUNCTION F_BUSCAF. O propósito é verificar quanto vezes esta mesma FUNCTION é executada quando se utilizando do RESULT_CACHE e quando não.
Agora, vamos comparar as execuções:
A FUNCTION F_BUSCAF será chamada sem a utilização do RESULT_CACHE, através do bloco anônimo abaixo:
SET serveroutput ON
BEGIN
dbms_output.Put_line(F_buscaf(1).my_id
||' - '
||F_buscaf(1).my_name
||' - '
||F_buscaf(1).salary);
END;
Atente-se que “RODOU” foi impresso três vezes, exatamente a mesma quantidade que a FUNCTION F_BUSCAF foi chamada no bloco anônimo. Uma para buscar o MY_ID, outra para buscar MY_NAME e a terceira para buscar SALARY.
Agora, a FUNCTION F_BUSCAF se utilizará do RESULT_CACHE. Vamos recompilar a função, conforme script abaixo adicionando o keyword RESULT_CACHE antes do IS:
CREATE OR replace FUNCTION F_buscaf(v_myid IN temp_teste.my_id%TYPE)
RETURN temp_teste%ROWTYPE RESULT_CACHE
IS
v_return temp_teste%ROWTYPE;
BEGIN
SELECT my_id,
my_name,
salary
INTO v_return.my_id, v_return.my_name, v_return.salary
FROM temp_teste
WHERE my_id = 1;
dbms_output.Put_line('RODOU');
RETURN v_return;
END f_buscaf;Executaremos o bloco anônimo:
SET serveroutput ON
BEGIN
dbms_output.Put_line(F_buscaf(1).my_id
||' - '
||F_buscaf(1).my_name
||' - '
||F_buscaf(1).salary);
END;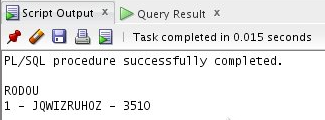
Agora “RODOU” é impresso apenas uma vez e todas as informações solicitadas foram retornadas nesta única execução. Ou seja, as informações foram recuperadas do cache, haja vista que necessitava, de fato, de uma só passagem para se conhecer o conteúdo de MY_ID, MY_NAME e SALARY.
Ainda, caso, novamente seja solicitada a FUNCTION F_BUSCAF esta não precisaria ser executada, já que seu retorno está em cache e “RODOU” não seria impresso nenhuma vez. Se a tabela TEMP_TESTE sofrer alteração em seu conteúdo o cache é refeito considerando estas alterações.
Existe a possibilidade de utilizar o hint /*+ RESULT_CACHE */ para query’s, bem como “forçar” o banco de dados a se utilizar do Result Cache mesmo que este não esteja declarado no código/query alterando o parâmetro de sistema result_cache_mode para FORCE. Contudo, o tema é extenso e discutirei em outro artigo apresentando os planos de execução das execuções.
*Todos os conteúdos dos parâmetros de sistema, aqui exposto, possuem valores ilustrativos e em seu ambiente deverá ser avaliado o preenchimento correto para melhor aderência e performance.
Referências