

Forall e Bulk Collect
Agilidade é a palavra do momento e tempo é dinheiro. É neste sentido que os bancos de dados sofrem, pois são sempre as mesmas histórias: o banco tá lento, nada funciona, liga para o DBA.
É certo, também, que grande parte das implementações é testada utilizando uma massa de dados aquém do que de fato será trabalhado no dia a dia. Isto dá uma ideia errada de performance, pois no ambiente de desenvolvimento tudo funciona como uma bala. Já na produção existe uma degradação no tempo de resposta por ter um cenário de dados bem diferente e muito maior.
Tuning SQL não é a resolução de todos os problemas e não vai deixar seu banco gravando e lendo em milissegundos. O assunto é bem mais amplo do que somente isso. Contudo, a utilização de algumas técnicas podem diminuir a dor de cabeça e melhorar a performance de grande parte das implementações.
Neste sentido, abaixo, é apresentado o FORALL combinado com o BULK COLLECT para atualização de uma tabela comparando-o com um For Update utilizando Current OF e o percentual de ganho em desempenho.
Para o teste, primeiramente, vamos criar uma tabela com 50 mil registros e com apenas três colunas. O ID será o ROWNUM e os campos MY_NAME e SALARY serão preenchidos utilizando a package DBMS_RANDOM. Utilize o script abaixo para criar a tabela temp_teste:
CREATE TABLE temp_teste AS
(SELECT ROWNUM my_id,
dbms_random.String('U', 10) my_name,
Round(dbms_random.Value(1, 7000)) salary
FROM dual
CONNECT BY LEVEL <= 50000 -- quantidade de registro a serem criados
)Para efetuar a comparação foi criado o bloco anônimo abaixo e utilizado a package DBMS_UTILITY para captar o tempo de atualização dos registros. A ideia do código é aumentar todos os salários em 10%, ou seja, 50 mil linhas serão atualizadas.
SET serveroutput ON
DECLARE
CURSOR v_cursor_one IS
SELECT my_id,
salary,
ROWID idlinha
FROM temp_teste;
TYPE trow_type
IS TABLE OF v_cursor_one%ROWTYPE INDEX BY PLS_INTEGER;
CURSOR v_cursor_two IS
SELECT my_id,
salary
FROM temp_teste
FOR UPDATE;
trow TROW_TYPE;
v_time_i_one NUMBER;
v_time_i_two NUMBER;
v_time_f_one NUMBER;
v_time_f_two NUMBER;
BEGIN
---- ATUALIZAÇÃO COM FORALL + BULK COLLECT
v_time_i_one := dbms_utility.Get_time();
OPEN v_cursor_one;
LOOP
FETCH v_cursor_one bulk collect INTO trow limit 5000;
exit WHEN trow.count = 0;
forall nx IN 1 .. trow.count
UPDATE temp_teste
SET salary = salary * 1.1
WHERE ROWID = Trow(nx).idlinha;
COMMIT;
END LOOP;
v_time_f_one := ( dbms_utility.get_time - v_time_i_one ) / 100;
dbms_output.Put_line('Atualizacao com Forall + Bulk Collect: '
|| v_time_f_one
|| ' segundos.');
CLOSE v_cursor_one;
---- ATUALIZAÇÃO COM CURRENT OF
v_time_i_two := dbms_utility.Get_time();
FOR v_crsr IN v_cursor_two LOOP
UPDATE temp_teste
SET salary = salary * 1.1
WHERE CURRENT OF v_cursor_two;
END LOOP;
COMMIT;
v_time_f_two := ( dbms_utility.get_time - v_time_i_two ) / 100;
dbms_output.Put_line('Atualizacao com Current OF: '
|| v_time_f_two
|| ' segundos');
dbms_output.Put_line('Ou seja, '
|| Round(( v_time_f_two * 100 ) / v_time_f_one, 2)
|| '% mais rapido.');
END;Veja que com FORALL + BULK COLLECT o ganho de performance chega a 389% em comparação ao FOR UPDATE.
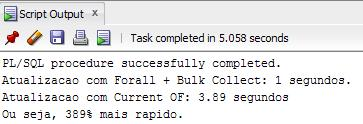
Para quem não está familiarizado, o CURRENT OF traz para chave de busca do registro o ROWID, ocasionando uma busca rápida das informações.
Alguns podem questionar que com BULK COLLECT o commit está sendo emitido a cada 5000 registros enquanto com o FOR UPDATE foi feito para os 50 Mil registros de uma vez. Pode-se alterar a lógica para o FOR UPDATE e emitir o commit para a mesma quantidade de registro, mas haveria mais trocas de contextos e, talvez, venha, até mesmo, piorar o tempo de gravação.
Ainda, utilize-se do BULK COLLECT com parcimônia, haja vista que pode representar um alto consumo da memória da PGA, principalmente se forem utilizado diversos processos paralelos com esta mesma prática e assim prejudicar a desempenho de todo o banco de dados, criando um problema ainda maior. Para isso é muito importante acompanhar e alinhar junto ao DBA um limite que não prejudique o desempenho e determinar este número através do delimitador LIMIT, que no exemplo acima está como 5000;
Referências