

Using Collections and Records (Parte 2)
No artigo anterior foi abordado o assunto de VARRAY – matrizes e vetores– neste artigo será a continuação de Records and Collections in PL/SQL (Registros e Coleções no PL/SQL) com o assunto de: NESTED TABLES – Tabelas Aninhadas – e no próximo artigo será abordado as Associative Array (Index-by table) – Matrizes Associativas.
Uma tabela aninhada nada mais é do que uma tabela incorporada dentro de outra, onde você pode inserir, atualizar e excluir elementos (e não registros, lembre-se sempre disto) de forma individual em uma tabela aninhada, isto é, as tabelas aninhadas são flexíveis, ao contrário de um VARRAY, onde os elementos ali contidos podem apenas serem modificados como um todo e devem conter um número fixo de elementos. Uma tabela aninhada não possuí um tamanho máximo de elementos e o desenvolvedor pode armazenar um número de elementos conforme a sua necessidade. (PRICE, 2009)
As linhas de uma tabela aninhada são armazenadas sem nenhuma ordem específica, mas quando as informações de uma tabela aninhada são recuperadas em uma variável PL/SQL, as linhas recebem subscritos consecutivos começando em 1, isto torna a tabela aninhada uma matriz a linhas individuais.
Inicialmente as tabelas aninhadas são densas, ao contrário de uma matriz, que não é possível excluir elementos de forma individual, mas no caso das tabelas aninhadas é possível efetuar esta exclusão de elementos de forma individual, isto torna a tabela aninhada dinâmica, onde deixará lacunas nos seus índices, mas o Oracle irá interpretar que o próximo elemento da tabela estará no próximo índice preenchido com algum elemento, ou seja, mesmo o elemento estando nulo (null) o Oracle irá percorrer para próximo o índice, e assim sucessivamente até encontrar o próximo índice preenchido por algum elemento que não esteja nulo (null). (MOORE, 2009)
Conforme a documentação do Oracle, existem algumas vantagens e desvantagens em se utilizar uma tabela aninhada, comparado com as VARRAYS e Matrizes Associativas, quando:
- Uma tabela aninhada pode ser armazenada em uma coluna do banco de dados, ou seja, pode-se usar a tabela aninhada para simplificar as operações em SQL que ingressar em uma tabela de coluna única com uma tabela maior.
- Os valores do índice não são consecutivos, ou possa possuir valores nulos dentro dos elementos dos índices;
- Não há um número definido de valores de índice, ou seja, não possuí limite de tamanho e não há a necessidade de fixar o tamanho da tabela;
- Deve-se excluir ou atualizar alguns elementos, mas não todos os elementos ao mesmo tempo, ao contrário do VARRAY;
- Poderia ser criado uma tabela de pesquisa separada, com várias entradas para cada linha da tabela principal, e acessá-lo através de consultas de associação;
- Os dados de uma tabela aninhada são armazenados em uma tabela de armazenamento (uma tabela gerada pelo próprio sistema do banco de dados Oracle). Quando é efetuado o acesso há uma tabela aninhada, o banco de dados junta a tabela aninhada com sua tabela de armazenamento, tornando-as próprias para as consultas e atualizações que afetam apenas alguns elementos da coleção;
- A desvantagem de uma tabela aninhada é que, não se pode confiar na ordem dos índices, isto porque, pode-se excluir e incluir novos índices de forma dinâmica, e o banco de dados não preserva a ordem dos elementos, sendo ocasionados por estarem nulos. (MOORE, 2009)
Os comandos que podem ser utilizados para as NESTED TABLES são os mesmos que para os VARRAYS, veja abaixo a mesma tabela que foi mostrada no artigo anterior (apenas para recordar): (BURLESON, 2008)
|
COUNT |
Retorna o número de elementos de um VARRAY. |
|
EXISTS |
Retorna um valor booleano verdadeiro se o elemento no índice especificado exista, caso contrário retornará falso. |
|
EXTEND |
Aumenta o tamanho da matriz por 1 ou pelo número especificado. Não pode ser usado em matrizes associativas. |
|
FIRST |
Navega para o primeiro elemento da matriz. |
|
LAST |
Navega para o último elemento da matriz. |
|
NEXT |
Navega para o próximo elemento da matriz. |
|
PRIOR |
Navega para o elemento anterior da matriz. |
|
TRIM |
Remove o último elemento da matriz. Não pode ser usado em matrizes associativas. |
|
DELETE |
Remove todos os elementos de uma matriz. |
|
LIMIT |
Mostra o limite de tamanho de uma matriz. |
O comando abaixo, é criado uma NESTED TABLE do tipo VARCHAR2 com o nome de TABLE_NAMES, e acrescentado alguns nomes para efetuar os testes e mostrar o exemplo dos nomes listados dentro de uma tabela aninhada, com um índice para o acesso.
EXEMPLO 01:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO', 'BELTRANO');
BEGIN
DBMS_OUTPUT.PUT_LINE('NOME É: ' || vNome(1));
END;RESULTADO 01:
bloco anônimo concluído
NOME É: LEANDRO MIOZZO BONATOA variável “vNome” recebe uma serie de nomes de uma tabela aninhada TABLE_NAMES e o comando acima apenas identificou qual é o nome posicionado no índice 1, lembrando que os índices em tabelas aninhadas se iniciam sempre na posição 1 e nunca em 0. Se executar este mesmo comando, porém substituindo apenas a posição de 1 para 0, ocorrerá o seguinte erro:
RESULTADO 02:
ORA-06532: Subscrito além do limiteIsto porque o limite de quantidade de valores não pode ser menor que 1. Mas há outro tipo de erro de índices quando utiliza-se tabelas aninhadas, que é quando o índice ultrapassa a quantidade de elementos disponíveis na tabela, e ocorre o seguinte erro:
RESULTADO 03:
ORA-06533: Subscrito acima da contagemMas quando o comando DELETE, para deletar um dos elementos, também não será possível acessar o mesmo, pois o registro não será encontrado, ocorrerá a famosa exceção de NO_DATA_FOUND. Abaixo o comando executado seguido de seu resultado:
EXEMPLO 02:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO', 'BELTRANO');
BEGIN
vNome.DELETE(1);
DBMS_OUTPUT.PUT_LINE('NOME É: ' || vNome(1));
END;RESULTADO 04:
ORA-01403: dados não encontradosNos próximos exemplos, serão efetuadas as execuções de funções de repetição.
EXEMPLO 03:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO','BELTRANO');
i integer := vNome.FIRST;
BEGIN
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT_LINE('NOME É: ' || vNome(I));
I := vNome.NEXT(I);
END LOOP;
END;RESULTADO 05:
bloco anônimo concluído
NOME É: LEANDRO MIOZZO BONATO
NOME É: JOÃO DA SILVA SAURO
NOME É: FULANO
NOME É: BELTRANONo caso acima, ao executar todos os elementos contidos na tabela aninhada, observe que é necessário criar uma variável para receber a posição do índice, atribuir a ela a primeira posição, e utilizá-la para percorrer por toda a tabela, também se faz necessário atribuir algum valor de início para ela, ou atribuir novamente um valor para o seu índice dentro do WHILE, para que ela possa prosseguir com a leitura dos elementos. No exemplo utiliza-se o comando FIRST, para buscar a primeira posição e o comando NEXT, para buscar a próxima posição da tabela aninhada.
Por exemplo, um destes elementos durante a repetição deixe de existir, ou fosse deletado, então o erro de dados não encontrados (NO_DATA_FOUND) é apresentado no resultado. Com isso precisa-se sempre ater a criar um tratamento para caso este tipo de situação venha surgir, segue o exemplo com o tratamento:
EXEMPLO 04:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO','BELTRANO');
i integer := vNome.FIRST;
BEGIN
vNome.delete(i);
WHILE i IS NOT NULL LOOP
IF vNome.EXISTS(I) THEN
DBMS_OUTPUT.PUT_LINE('NOME É: ' || vNome(I));
I := vNome.NEXT(I);
ELSE
DBMS_OUTPUT.PUT_LINE('NÃO EXISTE A POSIÇÃO ' || I);
I := vNome.NEXT(I);
END IF;
END LOOP;
END;RESULTADO 06:
bloco anônimo concluído
NÃO EXISTE A POSIÇÃO 1
NOME É: JOÃO DA SILVA SAURO
NOME É: FULANO
NOME É: BELTRANOÉ possível utilizar também o comando TRIM, que efetua a exclusão da quantidade de elementos em seu parâmetro de forma decrescente, por exemplo, a tabela aninhada possuí 10 posições e ao utilizar o comando TRIM para 5 elementos, então apenas sobrará os 5 primeiros elementos e os últimos 5 elementos serão apagados da tabela aninhada.
EXEMPLO 05:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO','BELTRANO');
i integer := vNome.FIRST;
BEGIN
vNome.TRIM(3);
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT_LINE('NOME É: ' || vNome(I));
i := vNome.NEXT(I);
END LOOP;
END;RESULTADO 07:
bloco anônimo concluído
NOME É: LEANDRO MIOZZO BONATOAo contrário do comando DELETE, o comando TRIM, elimina a quantidade de elementos contidos em seu parâmetro de entrada, no exemplo acima, havia 4 elementos onde foi utilizado o comando TRIM, e sobrou apenas 1 elemento, sendo apenas o primeiro elemento.
O comando COUNT em uma NESTED TABLE, nada mais é do que o comando LAST, apenas na exceção de algum dos elementos ser deletados durante a execução do script. (MOORE, 2014)
EXEMPLO 06:
SET SERVEROUTPUT ON;
DECLARE
TYPE TABLE_NAMES IS TABLE OF VARCHAR2(30);
vNome TABLE_NAMES := TABLE_NAMES('LEANDRO MIOZZO BONATO','JOÃO DA SILVA SAURO', 'FULANO','BELTRANO');
i integer := vNome.FIRST;
BEGIN
DBMS_OUTPUT.PUT_LINE('Quantidade antes: ' || vNome.COUNT);
DBMS_OUTPUT.PUT_LINE('Último elemento antes: ' || vNome.LAST);
vNome.DELETE(1);
DBMS_OUTPUT.PUT_LINE('Quantidade depois: ' || vNome.COUNT);
DBMS_OUTPUT.PUT_LINE('Último elemento depois: ' || vNome.LAST);
END;RESULTADO 08:
bloco anônimo concluído
Quantidade antes: 4
Último elemento antes: 4
Quantidade depois: 3
Último elemento depois: 4No caso das tabelas aninhadas pode-se também criar uma coleção de TYPES, definindo e declarando variáveis para posteriormente poder acessá-las e efetuar as transações no banco de dados necessárias.
O exemplo abaixo, deve-se declarar a variável com seu respectivo nome o seu tipo, se é tabela aninhada, VARRAY ou uma matriz associativa e então identificar qual o tipo do dado que irá ser utilizado (VARCHAR2, NUMBER, DATE, etc.).
EXEMPLO 07:
SET SERVEROUTPUT ON;
DECLARE
CURSOR curNomLst is SELECT FIRST_NAME FROM EMPLOYEES WHERE ROWNUM <= 10;
TYPE tNomLst IS TABLE of EMPLOYEES.FIRST_NAME%TYPE;
refNomLst tNomLst := tNomLst();
vCount INTEGER :=0;
BEGIN
FOR N IN curNomLst LOOP
vCount := vCount +1;
refNomLst.extend;
refNomLst(vCount) := N.FIRST_NAME;
DBMS_OUTPUT.PUT_LINE('EMPLOYEE FIRST_NAME('||VCOUNT||'):'||REFNOMLST(VCOUNT));
END LOOP;
END;RESULTADO 09:
bloco anônimo concluído
EMPLOYEE FIRST_NAME(1):Ellen
EMPLOYEE FIRST_NAME(2):Sundar
EMPLOYEE FIRST_NAME(3):Mozhe
EMPLOYEE FIRST_NAME(4):David
EMPLOYEE FIRST_NAME(5):Hermann
EMPLOYEE FIRST_NAME(6):Shelli
EMPLOYEE FIRST_NAME(7):Amit
EMPLOYEE FIRST_NAME(8):Elizabeth
EMPLOYEE FIRST_NAME(9):Sarah
EMPLOYEE FIRST_NAME(10):DavidNo exemplo acima, é executado um cursor de uma consulta na tabela EMPLOYEES (funcionários) para o campo de FIRST_NAME (primeiro nome), apenas limita-se a quantidade de registros para 10, para utilizar no exemplo. Em seguida define-se três variáveis, uma do tipo tabela, com um campo do tipo da coluna FIRST_NAME da tabela EMPLOYEES (seria o tipo VARCHAR2, em resumo). E outra definimos do tipo da referência da tabela criada anteriormente, inicializando com os valores da tabela, e por fim define-se uma variável contadora do tipo inteiro.
Para atribuir os valores do cursor à tabela aninhada e em seguida poder acessar os dados, deve-se criar um LOOP onde é definido como N tendo os registros do cursor CURNOMLST, então para que seja atribuído o valor à tabela aninhada, propriamente dito, deve-se estender o tamanho da tabela para que caiba os registros, pois a mesma não possuí nenhum elemento. Em seguida é atribuído o valor do cursor em um elemento no respectivo índice da variável VCOUNT.
Também se atribui à uma NESTED TABLE mais de uma coluna no cursor, que o Oracle irá interpretar normalmente. Segue exemplo abaixo:
EXEMPLO 08:
SET SERVEROUTPUT ON;
DECLARE
CURSOR curNomLst is SELECT FIRST_NAME, last_name, SALARY FROM EMPLOYEES WHERE ROWNUM <= 10;
TYPE tNomLst IS TABLE of EMPLOYEES%ROWTYPE;
refNomLst tNomLst := tNomLst();
vCount INTEGER :=0;
BEGIN
FOR N IN curNomLst LOOP
vCount := vCount +1;
refNomLst.extend;
refNomLst(vCount).first_name := N.FIRST_NAME;
refNomLst(vCount).LAST_name := N.LAST_NAME;
refNomLst(vCount).SALARY := N.SALARY;
DBMS_OUTPUT.PUT_LINE('EMPLOYEE FIRST_NAME('||VCOUNT||'):'||REFNOMLST(VCOUNT).FIRST_NAME
|| ' - LAST_NAME: ' || REFNOMLST(VCOUNT).LAST_NAME
|| ' - SALARY: ' || REFNOMLST(VCOUNT).SALARY);
END LOOP;
END;RESULTADO: 10
bloco anônimo concluído
EMPLOYEE FIRST_NAME(1):Steven - LAST_NAME: King - SALARY: 15000
EMPLOYEE FIRST_NAME(2):Neena - LAST_NAME: Kochhar - SALARY: 17000
EMPLOYEE FIRST_NAME(3):Lex - LAST_NAME: De Haan - SALARY: 17000
EMPLOYEE FIRST_NAME(4):Alexander - LAST_NAME: Hunold - SALARY: 9000
EMPLOYEE FIRST_NAME(5):Bruce - LAST_NAME: Ernst - SALARY: 6000
EMPLOYEE FIRST_NAME(6):David - LAST_NAME: Austin - SALARY: 4800
EMPLOYEE FIRST_NAME(7):Valli - LAST_NAME: Pataballa - SALARY: 4800
EMPLOYEE FIRST_NAME(8):Diana - LAST_NAME: Lorentz - SALARY: 4200
EMPLOYEE FIRST_NAME(9):Nancy - LAST_NAME: Greenberg - SALARY: 12008
EMPLOYEE FIRST_NAME(10):Daniel - LAST_NAME: Faviet - SALARY: 9000No exemplo acima, as colunas do SELECT, apenas altera-se a referência da tabela aninhada que era feita antes diretamente para a coluna de FIRST_NAME para um ROWTYPE, que nada mais é do que a referência da linha toda. Consequentemente com isso deve-se acrescentar na referência das colunas da tabela aninhada, os campos que receberão os valores, e também uma grande mudança no momento de referencia-los é acrescentar após o índice da tabela aninhada o nome do campo, ao contrário de quando se tem apenas uma coluna não há a necessidade de referencia-lo após o índice.
Contudo as NESTED TABLES possuem recursos mais poderosos do que apenas programação “pura” em PL/SQL, elas permitem se criar colunas em tabelas físicas, em resumo, é uma tabela de dados inteira, com suas respectivas propriedades, dentro de apenas uma coluna de tabela física. Abaixo os exemplos mostram como poderá ser utilizado tal recurso, e também como pode-se manipular os dados dentro desta coluna/tabela.
EXEMPLO 09:
CREATE TYPE EMPLOYEES_ELEMENTS AS OBJECT (
EMPLOYEE_ID NUMBER(8,0),
FIRST_NAME VARCHAR2(20),
LAST_NAME VARCHAR2(25),
EMAIL VARCHAR2(25),
PHONE_NUMBER VARCHAR2(20),
HIRE_DATE DATE,
JOB_ID2 VARCHAR2(10),
SALARY NUMBER(8,2),
COMMISSION_PCT NUMBER(2,2),
MANAGER_ID NUMBER(6),
DEPARTMENT_ID NUMBER(4)
);
CREATE TYPE EMPLOYEES_TABLE AS TABLE OF EMPLOYEES_ELEMENTS;
CREATE TABLE EMPLOYEE_COPY (
SEQ_EMPLOYEE NUMBER(8,0) NOT NULL ,
EMPLOYEE_INFO EMPLOYEES_TABLE,
CONSTRAINT EMPLOYEE_COPY_PK PRIMARY KEY (SEQ_EMPLOYEE) ENABLE
)
NESTED TABLE EMPLOYEE_INFO STORE AS EMPLOYEES_INFOS;
CREATE SEQUENCE SEQ_EMPLOYEE_COPY INCREMENT BY 1 START WITH 1 MAXVALUE 999999999999 MINVALUE 1 NOCACHE ORDER;
RESULTADO 11:
TYPE EMPLOYEES_ELEMENTS compilado
TYPE EMPLOYEES_TABLE compilado
table EMPLOYEE_COPY criado.
sequence SEQ_EMPLOYEE_COPY criado.No exemplo acima, cria-se um TYPE de OBJECT, que criará o objeto da tabela aninhada com todas as colunas necessárias para este exemplo. Replicando a tabela EMPLOYEES, com todos os tipos de dados e nomes de campos. Em seguida, é efetuada a criação de um novo TYPE de TABLE do TYPE criado anteriormente (EMPLOYEES_ELEMENTS), este TYPE estará referenciando e buscando todas as informações de propriedades criados no primeiro TYPE. Por fim, cria-se uma tabela cópia (EMPLOYEE_COPY) databela de EMPLOYEES, um campo da sequência é referenciado, apenas para a coluna do TYPE (EMPLOYEES_TABLE), após o comando de criação da tabela, deve-se indicar que a mesma possuí colunas e propriedades do tipo NESTED TABLE e o campo que está receberá o recurso é o EMPLOYEE_INFO, e será armazenado os dados no TYPEEMPLOYEES_INFOS. Cria-se também uma sequência para nos auxiliar no momento de inserir os registros da tabela, para a primeira coluna SEQ_EMPLOYEE, chamada de SEQ_EMPLOYEE_COPY.
Observe que na prática como funciona, segue o exemplo abaixo, para efetuar a operação, onde se faz uma pequena automação para o comando INSERT.
EXEMPLO 10:
DECLARE
CURSOR curEmployees is SELECT * FROM EMPLOYEES;
BEGIN
FOR N IN curEmployees LOOP
INSERT INTO EMPLOYEE_COPY (SEQ_EMPLOYEE, EMPLOYEE_INFO)
VALUES (SEQ_EMPLOYEE_COPY.NEXTVAL, EMPLOYEES_TABLE( EMPLOYEES_ELEMENTS ( N.EMPLOYEE_ID, N.FIRST_NAME, N.LAST_NAME, N.EMAIL, N.PHONE_NUMBER, N.HIRE_DATE, N.JOB_ID2, N.SALARY, N.COMMISSION_PCT, N.MANAGER_ID, N.DEPARTMENT_ID)));
END LOOP;
END;Efetua-se uma consulta comum na tabela de EMPLOYEES_COPY, e os registros que retornarão serão todos (com exceção do SEQ_EMPLOYEE) em uma coluna de um tipo de dado de NESTED TABLE, segue abaixo o resultado da consulta comum na tabela em questão. O exemplo abaixo está limitado a 5 registros apenas, para que o mesmo não se estenda muito, mas a quantidade real é de 107 registros.
EXEMPLO 11:
SELECT * FROM EMPLOYEE_COPY;RESULTADO 12:
SEQ_EMPLOYEE EMPLOYEE_INFO
------------ --------------------------------------------------
1HR.EMPLOYEES_TABLE(HR.EMPLOYEES_ELEMENTS(100,'Steven','King','SKING','515.123.4567','2003-06-17 00:00:00.0','AD_PRES',15000,NULL,100,90)) 2HR.EMPLOYEES_TABLE(HR.EMPLOYEES_ELEMENTS(101,'Neena','Kochhar','NKOCHHAR','515.123.4568','2005-09-21 00:00:00.0','AD_VP',17000,NULL,100,90))
3HR.EMPLOYEES_TABLE(HR.EMPLOYEES_ELEMENTS(102,'Lex','DeHaan','LDEHAAN','515.123.4569','2001-01-13 00:00:00.0','AD_VP',17000,NULL,100,90))
4HR.EMPLOYEES_TABLE(HR.EMPLOYEES_ELEMENTS(103,'Alexander','Hunold','AHUNOLD','590.423.4567','2006-01-03 00:00:00.0','IT_PROG',9000,NULL,102,60))
5HR.EMPLOYEES_TABLE(HR.EMPLOYEES_ELEMENTS(104,'Bruce','Ernst','BERNST','590.423.4568','2007-05-21 00:00:00.0','IT_PROG',6000,NULL,103,60))Para selecionar apenas um campo, ou apenas os campos desejados de uma NESTED TABLE pelo comando SELECT, deve-se apenas inserir na clausula do FROM a tabela que contém o campo, neste caso a EMPLOYEE_COPY, e então declarar uma nova tabela com o comando TABLE e indicar qual é a coluna NESTED TABLE da tabela referenciada da EMPLOYEE_COPY. Recomenda-se sempre criar “APELIDO” para as colunas referenciadas, para acessá-las mais facilmente depois. Segue o exemplo abaixo de como ficará a consulta no banco de dados, selecionando apenas alguns campos do objeto, o resultado é apenas o 5 primeiros registros.
EXEMPLO 12:
SELECT B.FIRST_NAME, B.LAST_NAME
FROM EMPLOYEE_COPY A, TABLE (A.EMPLOYEE_INFO) B;RESULTADO 13:
FIRST_NAME LAST_NAME
-------------------- -------------------------
Tayler Fox
Pat Fay
Mattea Marvins
Nandita Sarchand
Martha SullivanPode-se também utilizar um comando de consulta normalmente para a coluna, onde poderá ser utilizado os comandos no WHERE para efetuar filtros, de forma em que se utiliza a mesma lógica do que para um SELECT comum, porém deve-se acrescentar o campo que deseja comparar, o tipo da variável de tabela e a tabela referenciada, um pouco mais complicado, mas funcional da mesma forma. O exemplo abaixo mostra com detalhes como poderá ser feita esta consulta, o resultado é apenas o 5 primeiros registros.
EXEMPLO 13:
SELECT B.FIRST_NAME, B.LAST_NAME
FROM EMPLOYEE_COPY A, TABLE (A.EMPLOYEE_INFO) B
WHERE B.SALARY >= 10000RESULTADO 14:
FIRST_NAME LAST_NAME
-------------------- -------------------------
Pat Fay
Nancy Greenberg
Neena Kochhar
Lex De Haan
Harrison BloomPode-se, além do comando INSERT, utilizar outros comandos de manipulação em SQL (DML), como por exemplo, o UPDATE e o DELETE. O exemplo abaixo mostra como pode ser executado o comando de atualização de registros.
EXEMPLO 14:
UPDATE TABLE(SELECT A.EMPLOYEE_INFO
FROM EMPLOYEE_COPY A, TABLE (A.EMPLOYEE_INFO) B
WHERE B.EMPLOYEE_ID = 100
) B
SET B.FIRST_NAME = 'LEANDRO BONATO'EXEMPLO 15:
SELECT B.FIRST_NAME
FROM EMPLOYEE_COPY A, TABLE (A.EMPLOYEE_INFO) B
WHERE B.EMPLOYEE_ID = 100RESULTADO 15:
1 linhas atualizado.
FIRST_NAME
--------------------
LEANDRO BONATOEXEMPLO 16:
DELETE TABLE (SELECT A.EMPLOYEE_INFO
FROM EMPLOYEE_COPY A
WHERE A.SEQ_EMPLOYEE = 2
) A
WHERE A.FIRST_NAME = 'LEANDRO BONATO'RESULTADO 16:
1 linhas deletado.Quanto ao desempenho das NESTED´s TABLE´s testa-se da seguinte forma, primeiramente será inserido 1 000 000 (um milhão) de registros, utilizando comando INSERT do exemplo 10, onde apenas será acrescentado quantas vezes será repetido o comando de inserção, neste caso serão 10 000 vezes e 100 registros de cada vez. Este comando servirá também para inserir mais 1 000 000 de registros na tabela EMPLOYEES, e verificar qual foi mais rápido para inserir os dados. Em seguida será avaliado a quantidade de tempo para listar e consultar estes registros no banco de dados para compará-los.
EXEMPLO 17:
SET SERVEROUTPUT ON;
DECLARE
CURSOR curEmployees is SELECT * FROM EMPLOYEES;
BEGIN
FOR I IN 1..10000 LOOP
FOR N IN curEmployees LOOP
INSERT INTO EMPLOYEE_COPY (SEQ_EMPLOYEE, EMPLOYEE_INFO)
VALUES (SEQ_EMPLOYEE_COPY.NEXTVAL,
EMPLOYEES_TABLE(
EMPLOYEES_ELEMENTS(N.EMPLOYEE_ID, N.FIRST_NAME,
N.LAST_NAME, N.EMAIL, N.PHONE_NUMBER,
N.HIRE_DATE, N.JOB_ID2, N.SALARY,
N.COMMISSION_PCT, N.MANAGER_ID,
N.DEPARTMENT_ID
)
)
);
END LOOP;
END LOOP;
END;EXEMPLO 18:
SELECT COUNT(1) FROM EMPLOYEE_COPYRESULTADO 17:
bloco anônimo concluído.
Tarefa concluída em 612,671 segundos.
1070107 RegistrosPara o próximo exemplo se faz praticamente o mesmo INSERT, onde as mudanças serão na consulta que deverá ser EMPLOYEE_ID <= 206, para buscar apenas os mesmos que tinham na tabela EMPLOYEE_COPY, e criar uma variável contadora, já que não possuí uma sequência para utilizar do comando NEXTVAL. Deve-se também alterar algumas propriedades da tabela, no campo EMPLOYEE_ID deverá ser aumentado o seu limite para no mínimo 7 (eu coloquei 8 por boas práticas) e desativar a chave única do campo email (EMP_EMAIL_UK).
EXEMPLO 19:
SET SERVEROUTPUT ON;
DECLARE
CURSOR curEmployees is SELECT * FROM EMPLOYEES where EMPLOYEE_ID <= 206;
vCOUNT INTEGER := 207;
BEGIN
FOR I IN 1..10000 LOOP
FOR N IN curEmployees LOOP
INSERT INTO EMPLOYEES
VALUES (vCOUNT, N.FIRST_NAME, N.LAST_NAME, N.EMAIL, N.PHONE_NUMBER,
N.HIRE_DATE, N.JOB_ID2, N.SALARY, N.COMMISSION_PCT, N.MANAGER_ID,
N.DEPARTMENT_ID);
vCOUNT := vCOUNT + 1;
END LOOP;
END LOOP;
END;EXEMPLO 20:
SELECT COUNT(1) FROM EMPLOYEES;RESULTADO 18:
bloco anônimo concluído.
Tarefa concluída em 272,359 segundos.
1070107 RegistrosA ideia era fazer um comparativo entre dois INSERT´s, um normal entre a tabela de forma comum como conhecemos, e outro com a NESTED TABLE, com uma quantidade aproximada de registros, com isso tem-se um comparativo entre ambos para ver qual se comporta melhor.
Entende-se que no resultado as duas formas de inserção são muito parecidas em seu tempo de execução, testaremos agora uma consulta com aproximadamente 10% a 20% das tabelas para termos o tempo entre as duas e então mostrarei as vantagens e desvantagens de cada uma em cada situação.
EXEMPLO 21:
SELECT A.EMPLOYEE_ID, A.FIRST_NAME, A.LAST_NAME, A.SALARY FROM EMPLOYEE_COPY A, TABLE(EMPLOYEE_INFO) B
WHERE A.SALARY >= 10000;EXEMPLO 22:
SELECT COUNT(1) FROM EMPLOYEE_COPY WHERE SALARY >= 10000;RESULTADO 19:
200000 EXTRAÍDAS EM 10 SEGUNDOSAgora a mesma consulta, onde apenas é trocado as tabelas para visualizar quanto tempo demora para executar e quantos registros retornam após a consulta ser efetuada.
EXEMPLO 23:
SELECT A.EMPLOYEE_ID, A.FIRST_NAME, A.LAST_NAME, A.SALARY FROM EMPLOYEES A
WHERE A.SALARY >= 10000;EXEMPLO 24:
SELECT COUNT(1) FROM EMPLOYEES WHERE SALARY >= 10000;RESULTADO 20:
200020 LINHAS EXTRAÍDAS E, 12,063 SEGUNDOSTeoricamente a consulta na NESTED TABLE é mais rápida, observa-se que um comando de INSERT é muito mais demorado, praticamente 225% de diferença entre uma tabela simples e uma tabela aninhada. Para comprovar a diferença de cada um iremos agora executar o plano de explicação e o rastreamento automático de cada uma das consultas.
RESULTADO 21: (NESTED TABLE)

RESULTADO 22: (TABELA FÍSICA)

Observa-se que NESTED TABLE há muito mais cardinalidade de registros do que na tabela física, isto porque, todos os registros devem ser lidos e interpretados pela tabela aninhada e posteriormente interpretados pela tabela física
A desvantagem de uma NESTED TABLE é que não se pode criar um índice na coluna de EMPLOYEE_INFO, até porque não faria sentido, pois se fosse indexada as colunas, seriam todas as colunas pertencentes a um índice, isto é, todas as colunas da tabela EMPLOYEE estão dentro da NESTED TABLE, e isso não seria “uma boa prática”. Mas, se alterar a tabela física EMPLOYEES e acrescentar na coluna SALARY umíndice, o desempenho de nossa consulta não irá melhorar (devido à quantidade de registros), mas também no exemplo estará utilizando o novo índice criado, e também utilizando outras formas mais eficientes de resolver a consulta no banco de dados, mudando assim o plano de execução da consulta.
EXEMPLO 25:
CREATE INDEX EMP_ARTIGO_IDX ON EMPLOYEES (SALARY ASC);RESULTADO 23:
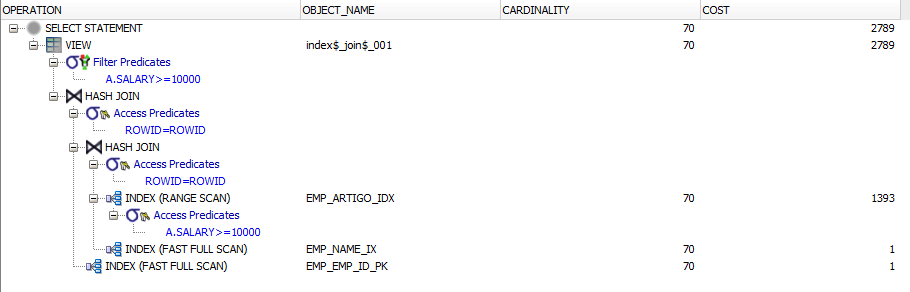
Com isto conclui-se que as NESTED TABLES quando se trata de operações mais comuns não se comportam muito bem, pois podem se tornar mais trabalhosa para se criar e também mais lentas no momento de retornar os dados. Mas são muito uteis quando utilizadas em PACKAGES, por exemplo, pois em uma PACKAGE o desenvolvedor poderá inserir vários tipos de variáveis e trabalhar com o PL/SQL sem problemas. Isto poderá trazer uma série de benefícios, como uma organização e algo mais próximo da para orientação à objetos, pois também não uma forma densa de programação, ou seja, o desenvolvedor pode optar por algo dinâmico, ao contrário dos VARRAY´s.
No próximo artigo, onde será o último desta série de artigos sobre registros e coleções no ORACLE, será abordado mais exemplos sobre as Tabelas Associativas ou tabela por índices (Associative array or index-by-table).
Referências
- PRICE, Jason. ORACLE DATABASE 11G SQL: DOMINE SQL E PL/SQL NO BANCO DE DADOS ORACLE. 2009.
- MOORE, Sheila. ORACLE® DATABASE PL/SQL LANGUAGE REFERENCE 11g RELEASE 1 (11.1) – B28370-05. 2009.
- ORACLE® DATABASE PL/SQL LANGUAGE REFERENCE 11g RELEASE 2 (11.2) – E25519-13. 2014.
- BURLESON, Don. ORACLE VARRAY EXAMPLES. 2008.
AGRADECIMENTOS
- CARLA GABRIELA DE SOUZA LEITES
- FABIO PELICER
- ALEXANDRE PIETROBELLI
- EM MEMÓRIA DE: LIVINO MIOZZO
Abraço

Obrigado pela bela exposição de como usar este tipo de estrutura.
Simplesmente , perfeita.