

ORACLE – Backup de grandes tabelas I
Nestes tempos em que o Big Data é alvo de todas as atenções, os velhos “backups” parecem ter deixado de ser uma preocupação. Mas, totalmente relacionado a um dos “Vs” do big data, o VOLUME de dados valiosos, sempre em crescimento, vai requerer atenção redobrada no desenho de políticas efetivas de backup/recover. Felizmente, o Oracle parece ter tudo que é necessário para enfrentar esse desafio.
Quais são os problemas ?
Os problemas que cercam a execução das cópias estão presentes em bancos de qualquer tamanho, mas seus efeitos se tornam mais graves à medida que o volume de dados aumenta. Podemos classificá-los como de:
Armazenamento
Quanto mais dados, maior a necessidade de espaço para armazenar suas cópias e, mesmo com o hardware mais acessível economicamente e os mecanismos de compressão, a necessidade de espaço só aumenta, exigindo dos administradores mediadas de contenção.
Tempo
A sobrecarga imposta aos recursos do servidor, particularmente no tempo da CPU, buses de Entrada/Saída e nos controladores de disco desvia recursos valiosos cujos principais destinatários são os sistemas de produção. Quanto mais ativo o ambiente, menor a fatia de recursos destinados a apoiar o backup, determinando assim os horários de execução e a duração dos mesmos.
Ferramentas
É um caso especial de limitação que se apresenta quando a empresa não investe em itens necessários para uma execução ótima das cópias. Ex. Licenças de software limitadas.
Enfrentando as limitações.
Antes de prosseguirmos, cabe um esclarecimento: não é casual que todas as ferramentas para enfrentar os desafios apresentados pelos backups estejam presentes em produto Oracle (RMAN). Afinal, mesmo antes do advento do Big Data a Oracle já lidava com grandes volumes de dados. Por este motivo, não enveredarei por estratégias que não utilizem RMAN por entender que, cedo ou tarde, cairei em limitações intransponíveis.
Como estamos ?
“Não se gerencia o que não se mede e não há sucesso no que não se gerencia”
(William Edwards Deming)
O desempenho do hardware nas operações de gravação e leitura (throughput) é fundamental no desenho de políticas de backup e crucial para a administração de operações. Tal é sua importância que na versão 11g foi disponibilizada uma procedure com a finalidade de medi-lo.
A procedure DBMS_RESOURCE_MANAGER.CALIBRATE_IO foi projetada para medir as respostas do dispositivo de armazenamento onde o banco está instalado, permitindo avaliar o desempenho do subsistema de armazenamento e determinar a origem dos problemas de I/O.
A procedure recebe como parâmetros de entrada: o número de discos físicos onde reside o banco de dados e a latência (demora) almejada para o sistema, retornando o número máximo de requisições de I/O por segundo que pode ser suportado pela estrutura de armazenamento (max_iops); o throughput máximo em MB/s e a média das latências (demoras), em milisegundos, na leitura de blocos de dados..
Para executá-la é necessário o privilégio de SYSDBA e algumas configurações prévias:
alter system set TIMED_STATISTICS=TRUE;E os datafiles devem estar sendo acessados no modo asynchronous I/O
Para checar o modo de acesso em uso, executamos a consulta:
SELECT d.name, i.asynch_io
FROM v$datafile d, v$iostat_file i
WHERE d.file# = i.file_no
AND i.filetype_name = 'Data File';A resposta esperada deverá ser similar a mostrada abaixo, com o modo assíncrono ligado (ON):
NAME ASYNCH_IO
-------------------------------------- ---------
C:...SYSTEM01.DBF ASYNC_ON
C:...SYSAUX01.DBF ASYNC_ON
C:...UNDOTBS01.DBF ASYNC_ON
C:...USERS01.DBF ASYNC_ON
C:...EXAMPLE01.DBF ASYNC_ON
C:APPRWORADATASTOREDATA01.DBF ASYNC_ON
C:APPRWORADATANONCRIT.DBF ASYNC_ONCaso contrário, alteramos o modo com:
ALTER SYSTEM SET filesystemio_options=setall SCOPE=SPFILE;Sendo necessária a reinicialização do banco para que o parâmetro surta efeito..
Conectamos com SYSDBA e executamos o bloco anonimo, lembrando que em RACs a carga será distribuído entre os nós.
DECLARE
l_latency PLS_INTEGER;
l_iops PLS_INTEGER;
l_mbps PLS_INTEGER;
BEGIN
DBMS_RESOURCE_MANAGER.calibrate_io (num_physical_disks => 1,
max_latency => 20,
max_iops => l_iops,
max_mbps => l_mbps,
actual_latency => l_latency);
END;
/Os resultados são sobregravados na view DBA_RSRC_IO_CALIBRATE a cada execução, e podem ser consultados como segue:
SELECT to_char(START_TIME,'DD/MM/YYYY HH24:mi:ss') Inicio
, to_char(END_TIME,'DD/MM/YYYY HH24:mi:ss') Final
, MAX_IOPS
, MAX_MBPS
, MAX_PMBPS
, LATENCY
, NUM_PHYSICAL_DISKS as “#DISKS”
FROM DBA_RSRC_IO_CALIBRATE;Obtendo uma resposta similar a:
Inicio Final MAX_IOPS MAX_PBPS MAX_PMBPS LATENCY #DISKS
------------------- ------------------- -------- -------- --------- ------- ------
27/09/2017 18:49:14 27/09/2017 19:01:47 62 26 9 15 1As operações de I/O, em média, são de 62MB/s, com uma latência de 15ms. É um PC bem lento ! Se houvessem mais discos, dois por exemplo, a média de I/O por segundo em cada disco, seria de: 62/2. Ou seja 31MB/s.
No computador usado nesta coleta, para aumentar o máximo de operações de I/O por segundo, seria necessária a substituição dos discos por outros de maior performance.
A procedure dá ao administrador elementos para demonstrar, neste caso, que a solução é a troca do hardware já que nenhuma aplicação profissional tolera níveis tão baixos de desempenho.
Enfrentando as limitações.
Tudo começa com uma primeira cópia(1) executada por meio do RMAN que, por não ter antecessoras, precisa copiar tudo que existe no banco de dados. É o chamado backup de nível zero ou backup-base. Nas próximas cópias, se comandadas de forma incremental, o RMAN lerá todos os blocos capturando apenas aqueles que foram alterados depois da execução da cópia anterior, desde que não estejam vazios.
Cópias incrementais, quando otimamente projetadas, evitam a duplicação de dados reduzindo assim o tempo execução e o espaço consumido em disco.
Backups incrementais ainda possuem duas características: podem ser cumulativos ou diferenciais. Nos cumulativos, cada nova cópia contém todos os dados modificados desde o backup-base (representados em negro no diagrama abaixo). Já os diferencias, contém apenas os blocos modificados a partir da cópia incremental anterior (em vermelho)
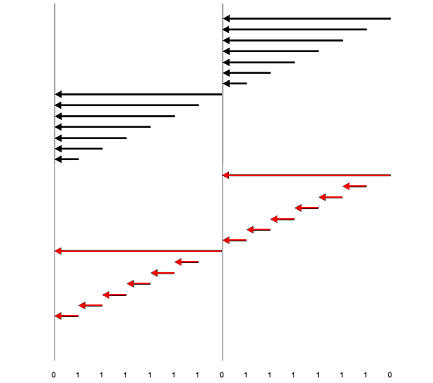
Se atribuirmos um valor de 1GB para as menores setas do diagrama acima perceberemos que o backup incremental cumulativo, em sua primeira execução, ocuparia 1GB de espaço em disco; na segunda execução, 2G e numa terceira, 3G. Para evitar o uso de 6G seria necessário um esforço de administração extra, removendo os backups anteriores após a execução de um atual. Note que mesmo assim, entre a execução e a limpeza, a cópia prévia teria que ser mantida. Outra característica negativa é que o tempo de execução de um backup cumulativo se torna maior a cada dia.
Já no backup for incremental diferencial, o espaço consumido seria de 3GB, aumentando 1GB por dia e não exigiria outros esforços administrativos.
Em linhas gerais, os comandos para implantar o que foi mencionado neste parágrafo são:
BACKUP incremental level 0 database;
BACKUP archivelog all delete all input;Os detalhes deste comando, que serão discutidos mais adiante, produzirá o BACKUP-BASE, devendo ser executado a intervalos regulares não diários.
Já diariamente, o backup incremental seria executado com os comandos:
BACKUP incremental level 1 database;
BACKUP archivelog all delete all input;Cada comando BACKUP gera um backup set, que é uma estrutura lógica que pode agrupar vários arquivos de banco de dados (datafiles), spfiles, arquivos de controle, etc., em um ou mais arquivos, denominados backup pieces. Em geral, um backup set tem apenas um backup piece.
Um backup piece é a estrutura física onde o backup está armazenado. É composto por um ou mais arquivos binários. Nos backups para disco, cada arquivo gerado é um backup piece.
A opção de ter um backup set para os archives e outro para os datafiles, reduzirá o tempo de leitura durante uma operação de Recover. Ademais, com a cláusula DELETE ALL INPUT, os archives são removidos do disco após a cópia, tornando-se assim mais um fator na otimização do uso do espaço.
Até aqui, como consequência do algoritmo empregado para execução do backup incremental, só poderemos falar em economia de espaço. Vejamos o porquê.
Nos backups incrementais, o RMAN ainda precisa ler todos os blocos de dados para identificar aqueles que foram alterados afetando assim o tempo de execução. Para obter economia de tempo em um backup incremental, faz-se necessário a habilitação do recurso Block Change Tracking (BCT). Com ele ativo, o endereço dos blocos alterados são gravados em um “tracking file”, permitindo ao RMAN identificar, sem a necessidade de uma leitura sequencial, quais blocos deverão ser adicionados ao backup, reduzindo assim o tempo de execução. Para habilitar este recurso, primeiro:
Verifique se o recurso do BCT está ou não ativo, por meio da consulta:
SELECT * FROM v$block_change_tracking;Caso não esteja ativo, habilite-o:
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING USING FILE '…/BLKTRK.F' [REUSE];Importante:
Dado que o tracking file terá um uso intenso, não o coloque junto aos Redo Log Files ou dos Archives pois há grande possibilidade de travamento do banco durante os Log Switches.
O BCT é um arquivo binário que não é levado em consideração pelo RMAN (!!!!)
Caso seja necessário desabilitá-lo, valha-se de:
ALTER DATABASE DISABLE BLOCK CHANGE TRACKING;A efetividade do uso do BCT pode ser acompanhada por meio da query:
SELECT file#
, avg(datafile_blocks) as “Média de Blocos”
, avg(blocks_read) as “Média de Blocos Lidos”
, avg(blocks_read/datafile_blocks) * 100 as "% Lidos para o backup"
FROM v$backup_datafile
WHERE incremental_level > 0
AND used_change_tracking = 'YES'
GROUP BY file#
ORDER BY file#;A combinação do backup incremental com o BCT terá impacto positivo na economia de tempo e de espaço.
O tamanho do tracking file será inicialmente de 10MB e crescerá com incrementos de igual tamanho. Sendo seu tamanho final atrelado à quantidade de blocos no banco, não crescerá indefinidamente.
Para estimar o tamanho atual do tracking file, utilize a seguinte query:
SELECT FILE#
, INCREMENTAL_LEVEL
, COMPLETION_TIME
, BLOCKS
, DATAFILE_BLOCKS
FROM V$BACKUP_DATAFILE
WHERE INCREMENTAL_LEVEL > 0
AND BLOCKS / DATAFILE_BLOCKS > .5
ORDER BY COMPLETION_TIME;Como pode ser visto, a view v$backup_datafile é uma fonte segura para basear a administração dos backups. Nela podemos verificar se um backup foi ou não incremental (INCREMENTAL_LEVEL), se o BCT foi usado para a cópia (USED_CHANGE_TRACKING) e avaliar o rendimento (antes/depois BCT)
select sum(BLOCKS_READ)/sum(DATAFILE_BLOCKS)
from v$backup_datafile
where USED_CHANGE_TRACKING = [‘NO’]['YES']
/Antes do aparecimento do RMAN, era comum economizar espaço utilizando a compressão por meio de utilitários do sistema operacional (gzip, compress, etc). Mas essa prática tem embutida a operação de descompactção antes da recuperação, aumentando seu tempo de execução. Já com o RMAN, quatro tipo de compressão de backups foram disponibilizadas eliminando a necessidade do uso de “compactadores. Eles são:
BASIC – algoritmo de compressão padrão
HIGH – adequado para ambientes onde a velocidade da rede seja o fator limitante por gerar menos tráfego.
MEDIUM – Recomendado para a maioria dos ambientes devido as relações entre compressão/velocidade
LOW – Menor impacto na taxa de transferência. Adequado para ambientes onde o fator limitante sejam os recursos da CPU.
Se o seu ambiente não padece de limitações de ferramentas, uma licença Advanced Compression Option será necessária para a utilização da compressão. Caso contrário, apenas a opção BASIC se faz disponível.
Para a execução de um backup com compressão, o comando apresentará a cláusla AS COMPRESSED em sua sintaxe e previamente, o tipo de compressão declarado :
CONFIGURE COMPRESSION ALGORITHM [‘BASIC’][‘LOW’][‘MEDIUM’][‘HIGH’];
BACKUP AS COMPRESSED BACKUPSET DATABASE PLUS archivelog delete all input;O que mais pode ser feito ?
Vamos utilizar o BACKUP .. VALIDATE que, pese a sua função principal ser a de checar a existência de blocos corrompidos, arquivos faltantes e se os backups podem ser restaurados, podemos utilizá-lo para levantar características do backup sem ter que efetuá-lo.
rman target /
RMAN> spool log to c:temprman.log
RMAN> backup validate incremental level 0 database;
RMAN> spool log off;Ao examinar o log gerado, algumas característica já podem ser identificadas como no extrato abaixo no qual vemos o paralelismo usado e o tempo decorrido na operação:
Iniciando backup em 02/10/17
utilizando o canal ORA_DISK_1
canal ORA_DISK_1: iniciando conjunto de backup em nível incremental do arquivo de dados 0
canal ORA_DISK_1: especificando arquivo[s] de dados no conjunto de backups
número do arquivo=00001 nome=C:...SYSTEM01.DBF do arquivo de dados de entrada
número do arquivo=00002 nome=C:...SYSAUX01.DBF do arquivo de dados de entrada
número do arquivo=00005 nome=C:...EXAMPLE01.DBF do arquivo de dados de entrada
número do arquivo=00006 nome=C:...STOREDATA01.DBF do arquivo de dados de entrada
número do arquivo=00003 nome=C:...UNDOTBS01.DBF do arquivo de dados de entrada
número do arquivo=00004 nome=C:...USERS01.DBF do arquivo de dados de entrada
número do arquivo=00007 nome=C:APPRWORADATANONCRIT.DBF do arquivo de dados de entrada
canal ORA_DISK_1: conjunto de backups concluído, tempo decorrido: 00:01:35A informação sobre o paralelismo e outros parâmetros em uso pode ser vista utilizando o comando SHOW ALL do RMAN. O paralelismo é mostrado como:
RMAN> SHOW ALL;
. . .
CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default
. . .Aumentemos o grau de paralelismo e verifiquemos o impacto no tempo decorrido.
RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 3 BACKUP TYPE TO BACKUPSET;
RMAN> spool log to c:temprman.log
RMAN> backup validate incremental level 0 database;
RMAN> spool log off;Como esperado, o backup agora utilizou três canais e por isso, reduziu o tempo de execução reduzido em 27,36%. Nada mal para um simples ajuste mas lembre-se, o paralelismo consome recursos e a partir de certo ponto, começa a impactar negativamente.
Iniciando backup em 02/10/17
utilizando o canal ORA_DISK_1
utilizando o canal ORA_DISK_2
utilizando o canal ORA_DISK_3
canal ORA_DISK_1: iniciando conjunto de backup em nível incremental do arquivo de dados 0
canal ORA_DISK_1: especificando arquivo[s] de dados no conjunto de backups
número do arquivo=00001 nome=C:...SYSTEM01.DBF do arquivo de dados de entrada
canal ORA_DISK_2: iniciando conjunto de backup em nível incremental do arquivo de dados 0
canal ORA_DISK_2: especificando arquivo[s] de dados no conjunto de backups
número do arquivo=00002 nome=C:...SYSAUX01.DBF do arquivo de dados de entrada
número do arquivo=00004 nome=C:...USERS01.DBF do arquivo de dados de entrada
número do arquivo=00007 nome=C:...NONCRIT.DBF do arquivo de dados de entrada
canal ORA_DISK_3: iniciando conjunto de backup em nível incremental do arquivo de dados 0
canal ORA_DISK_3: especificando arquivo[s] de dados no conjunto de backups
número do arquivo=00005 nome=C:...EXAMPLE01.DBF do arquivo de dados de entrada
número do arquivo=00006 nome=C:...STOREDATA01.DBF do arquivo de dados de entrada
número do arquivo=00003 nome=C:...UNDOTBS01.DBF do arquivo de dados de entrada
canal ORA_DISK_1: conjunto de backups concluído,tempo decorrido: 00:01:09Alteramos o tempo, agora vejamos o impacto da mudança de parametros para o espaço.
Para fins de comparação, tomamos um backup sem compressão e examinamos seu tamanho;
backup incremental level 0 database;
Como resultado, temos 5 arquivos totalizando 1.18Gb e gerados 00:01:56:
02/10/2017 14:22 9.797.632 O1_MF_NCNN0_TAG20171002T142052_DX4XGPZ5_.BKP
02/10/2017 14:22 652.615.680 O1_MF_NNND0_TAG20171002T142052_DX4XCORZ_.BKP
02/10/2017 14:22 528.269.312 O1_MF_NNND0_TAG20171002T142052_DX4XD0R4_.BKP
02/10/2017 14:22 79.806.464 O1_MF_NNND0_TAG20171002T142052_DX4XDJD9_.BKP
02/10/2017 14:22 98.304 O1_MF_NNSN0_TAG20171002T142052_DX4XGJO8_.BKP
5 arquivo(s) 1.270.587.392 bytesCom a compressão em seu padrão (“BASIC”) tomamos um novo backup.
CONFIGURE COMPRESSION ALGORITHM 'BASIC';
backup as compressed backupset incremental level 0 database;
02/10/2017 14:27 1.130.496 O1_MF_NCNN0_TAG20171002T142633_DX4XRTNN_.BKP
02/10/2017 14:27 196.026.368 O1_MF_NNND0_TAG20171002T142633_DX4XPBQC_.BKP
02/10/2017 14:27 104.783.872 O1_MF_NNND0_TAG20171002T142633_DX4XPKR2_.BKP
02/10/2017 14:27 23.977.984 O1_MF_NNND0_TAG20171002T142633_DX4XQ55K_.BKP
02/10/2017 14:27 98.304 O1_MF_NNSN0_TAG20171002T142633_DX4XRRVZ_.BKP
5 arquivo(s) 326.017.024 bytesOs mesmo 5 arquivos agora ocupam 0,303Gb. Ou seja 74,34% de economia de espaço.
Vejamos com compressão máxima.
CONFIGURE COMPRESSION ALGORITHM 'HIGH';
backup as compressed backupset incremental level 0 database;
02/10/2017 14:34 1.114.112 O1_MF_NCNN0_TAG20171002T143349_DX4Y58LY_.BKP
02/10/2017 14:36 157.999.104 O1_MF_NNND0_TAG20171002T143349_DX4Y3YXM_.BKP
02/10/2017 14:35 84.606.976 O1_MF_NNND0_TAG20171002T143349_DX4Y435P_.BKP
02/10/2017 14:34 21.774.336 O1_MF_NNND0_TAG20171002T143349_DX4Y46GH_.BKP
02/10/2017 14:34 98.304 O1_MF_NNSN0_TAG20171002T143349_DX4Y5D46_.BKP
5 arquivo(s) 265.592.832 bytesChegamos a 99,79% de economia. Conforme o tamanho e a características dos dados contidos no banco, este percentual pode e vai variar mas, definitivamente, a compressão economiza muito espaço.
Lembrando que esta opção pode incorrer em limitação de ferramentas se a empresa não detém a licença adequada.
Pessoal, a primeira parte termina aqui. Pretendo divulgar uma parte II onde abordarei situações mais complicadas. Até lá.