

Replicando dados com Kafka e Oracle CDC – Parte V
No primeiro artigo expliquei sobre quais os requisitos necessários para implementarmos a replicação de dados utilizando Kafka. No segundo artigo foi explicado como instalar o Confluent Platform, no terceiro artigo fizemos a instalação dos conectores e no quarto artigo mostrei como habilitar o CDC no banco de dados Oracle.
Nesse quinto e último artigo da série, mostrarei como configurar os conectores para que a replicação de dados seja possível.
Como já tinha citado nos outros artigos, a idéia não é se aprofundar muito e sim explicar o mínimo necessário para que o nosso objetivo seja concluído (replicação de dados). Porém, deixarei todas as referências para que você possa estudar e aprender cada vez mais sobre a Confluent Platform e seus conectores.
Banco de dados
Oracle19c_1 – Origem
Garanta que todos os passos do quarto artigo foram seguidos.
Oracle19c_2 – destino
No nosso banco de dados de destino, precisaremos criar no CDB um usuário para receber os dados oriundos da tabela de origem (TAB_TESTE_1 em oracle19c_1).
Utilize o mesmo script usado para criar o usuário oracle19c_1, também no oracle19c_2:
CREATE USER C##GPO IDENTIFIED BY < sua senha >
/
GRANT DBA TO C##GPO
/User C##GPO created.
Grant succeeded.Usuário do banco oracle19c_2 criado com sucesso ! 🙂
Conectores
O conector Oracle CDC será o nosso SOURCE e o JDBC o nosso SINK. Basicamente, o SOURCE é o que gera os dados para que o SINK consuma e persista.
Oracle CDC Source Connector
Arquivo de configuração
O conector Oracle CDC será o primeiro a ser configurado. Abaixo o arquivo de configuração que iremos utilizar. Salve-o como ConnOracleCDC.json:
{
"name": "ConnOracleCDCv1",
"config":{
"connector.class": "io.confluent.connect.oracle.cdc.OracleCdcSourceConnector",
"name": "ConnOracleCDCv1",
"tasks.max": "3",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"oracle.server": "oracle19c_1",
"oracle.port": "1521",
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"oracle.password": "<sua senha>",
"start.from":"snapshot",
"max.batch.size":"100",
"redo.log.topic.name": "redo-log-topic-cdc-v1",
"redo.log.corruption.topic": "corrupted-redo-log-topic-v1",
"redo.log.startup.polling.limit.ms": "300000",
"redo.log.consumer.request.timeout.ms": "60000",
"redo.log.consumer.bootstrap.servers": "broker:29092",
"redo.log.row.fetch.size":"5",
"emit.tombstone.on.delete": "true",
"output.table.name.field": " ",
"output.scn.field": " ",
"output.op.ts.field": " ",
"output.op.type.field": " ",
"output.current.ts.field": " ",
"output.row.id.field": " ",
"output.username.field": " ",
"numeric.mapping": "best_fit_or_double",
"behavior.on.unparsable.statement": "log",
"table.inclusion.regex":"ORCLCDB[.]C##GPO[.]TAB_TESTE_1",
"_table.topic.name.template_":"Set to an empty string to disable generating change event records",
"table.topic.name.template": "TAB-TESTE-V1",
"connection.pool.max.size": "10",
"topic.creation.groups": "redo",
"topic.creation.redo.include": "redo-log-topic-t-v1",
"topic.creation.redo.replication.factor": "1",
"topic.creation.redo.partitions": "1",
"topic.creation.redo.cleanup.policy": "delete",
"topic.creation.redo.retention.ms": "1209600000",
"topic.creation.default.replication.factor": "1",
"topic.creation.default.partitions": "3",
"topic.creation.default.cleanup.policy": "delete",
"snapshot.by.table.partitions": "true",
"query.timeout.ms": "600000",
"snapshot.row.fetch.size":"100"
}
}Vou comentar um pouco sobre as propriedades em negritos. Eles são necessários para se entender o funcionamento do conector.
| Propriedade | Descrição |
| name | nome do conector |
| key.converter | Serializador da chave do registro |
| value.converter | Serializador dos valores do registro |
| oracle.server | Endereço do banco de dados |
| oracle.port | Porta do banco de dados |
| oracle.sid | SID do banco de dados |
| oracle.username | Usuário de conexão do banco de dados |
| oracle.password | Senha do usuário do banco de dados |
| start.from | Posição do redo log |
| redo.log.topic.name | Nome do tópico do redo log |
| redo.log.corruption.topic | Nome do tópico para redo logs corrompidos |
| redo.log.consumer.bootstrap.servers | Endereço do broker |
| emit.tombstone.on.delete | Geração de tombstone records para o conector JDBC Sink |
| numeric.mapping | Map de precisão de tipos numéricos |
| behavior.on.unparsable.statement | Comportamento do conector a erros de parse |
| table.inclusion.regex | Expressão regular para definição da tabela a ser replicada |
| table.topic.name.template | Nome do tópico da tabela |
- key e value converter: Vamos utilizar o serializador JSON que não precisa do schema registry para funcionar.
- start.from: A opção escolhida é a snapshot, que faz a replicação dos dados já existentes na tabela
- redo.log.topic.name: O nome do nosso tópico para os redo logs será redo-log-topic-cdc-v1
- redo.log.corruption.topic: O nome do nosso tópico para os redo logs corrompidos será corrupted-redo-log-topic-v1
- redo.log.consumer.bootstrap.servers: O endereço do nosso broker é o broker:29092
- emit.tombstone.on.delete: Vamos deixar como true, para que sejam emitidos os tombstone records para o conector JDBC Sink para a indicação de uma operação de DELETE
- behavior.on.unparsable.statement: Será setado como log, para que erros de parse não parem a execução do conector e registre os erros no arquivo de log
- table.inclusion.regex: A expressão regular para a nossa tabela é ORCLCDB[.]C##GPO[.]TAB_TESTE_1
- table.topic.name.template: O nome do tópico para a nossa tabela será TAB-TESTE
Para se aprofundar mais sobre todas as propriedades disponíveis no conector, consulte a documentação oficial do Oracle CDC Connector.
JDBC Sink Connector
Arquivo de configuração
Agora vamos montar o arquivo de configuração do JDBC Sink. Abaixo os parâmetros que utilizaremos. Salve-o como ConnJDBCSink.json:
{
"name": "ConnJDBCSinkv1",
"config": {
"name": "ConnJDBCSinkv1",
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"tasks.max": "2",
"topics": "TAB-TESTE-V1",
"batch.size": "1",
"connection.url": "jdbc:oracle:thin:@oracle19c_2:1523/ORCLCDB",
"connection.user": "C##GPO",
"connection.password": < sua senha >,
"insert.mode": "upsert",
"table.name.format": "TAB_TESTE_1",
"pk.mode": "record_key",
"pk.fields": "EVENT_ID",
"auto.create": "true",
"auto.evolve": "false",
"delete.enabled": "true"
}
}| Propriedade | Descrição |
| name | nome do conector |
| key.converter | Serializador da chave do registro |
| value.converter | Serializador dos valores do registro |
| topics | Nome do tópico a ser lido pelo conector |
| connection.url | String de conexão JDBC ao banco de dados |
| connection.user | Usuário do banco de dados |
| connection.password | Senha do usuário do banco de dados |
| insert.mode | Método de inserção na tabela destino |
| table.name.format | Nome da tabela destino |
| pk.mode | Modo de chave primária |
| pk.fields | Campo(s) da chave primária |
| auto.create | Criação automática da tabela destino |
| auto.evolve | Replica inclusão de campos na tabela |
| delete.enabled | Modo de exclusão de registros |
- key e value converter: Deve ser o mesmo serializador utilizado no conector CDC.
- topics: Deve ser o mesmo gerado pelo conector CDC.
- insert.mode: Utilizaremos o modo upsert, que captura as inclusões e alterações feitas nos registros da tabela de origem.
- table.name.format: Utilizaremos o mesmo nome da tabela de origem (não é obrigatório).
- pk.mode: O modo upsert e delete necessitam que uma chave seja atribuída para fazer o controle das transações DML. Por isso será setado como true.
- pk.fields: A nossa tabela utiliza como chave o campo EVENT_ID.
- auto.create: Setaremos como true, para que o conector crie automaticamente a tabela.
- auto.evolve: Setaremos como true, apesar que não faremos alterações na estrutura da tabela (apenas menção pela importância).
- delete.enabled: Setaremos como true, pois queremos também capturar as exclusões de registro.
Para se aprofundar mais sobre todas as propriedades disponíveis no conector, consulte a documentação oficial do JDBC Sink Connector.
Subindo os conectores na Confluent Platform
Agora chegou o momento que mais esperávamos ! Vamos acessar o Control Center para subir os conectores !
http://localhost:9021/clusters
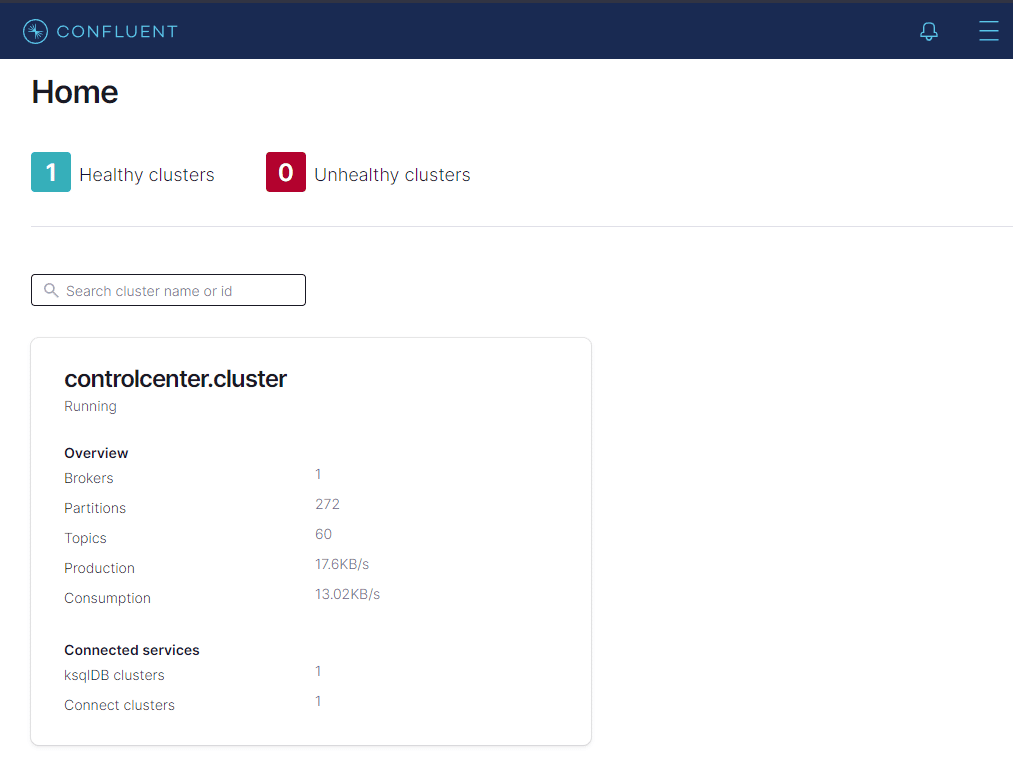
Veja que o cluster está rodando sem erros. Caso apareça como Unhealthy, verifique se algum dos containers não está executando e rode novamente o docker compose como explicado no segundo artigo.
Cliquemos em controlcenter.cluster
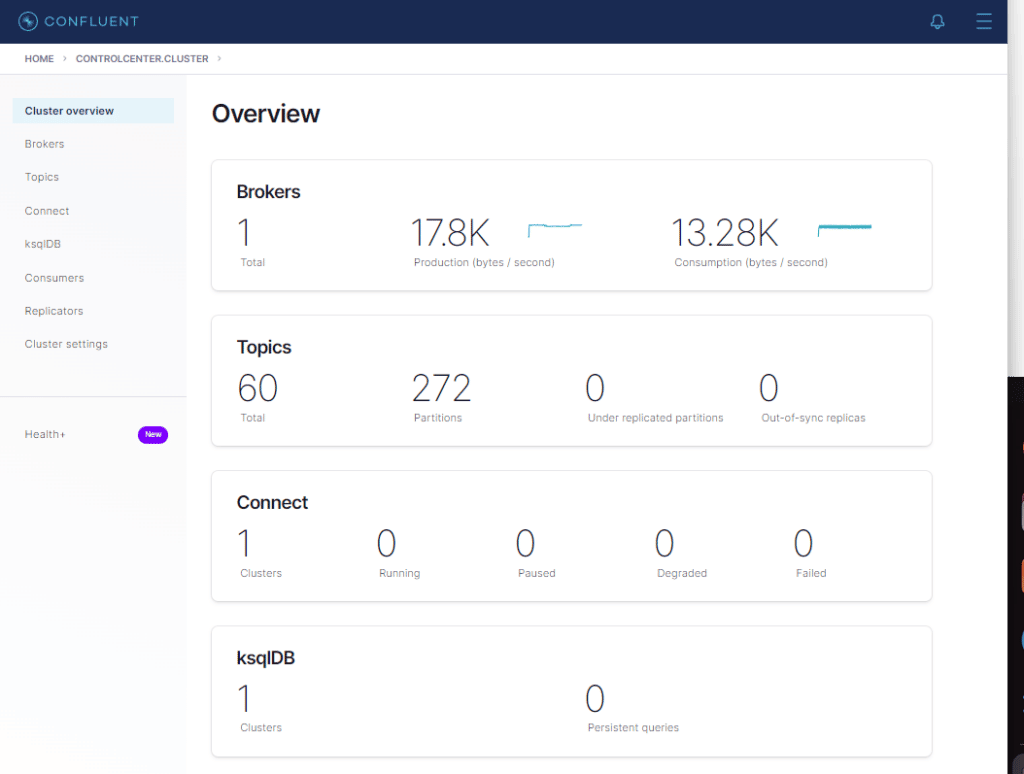
Cliquemos em Connect
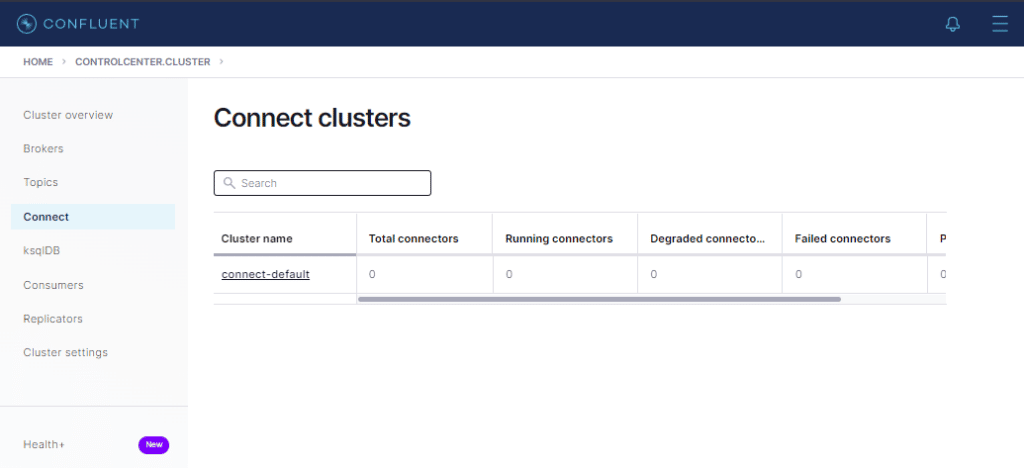
Observe que não há conectores configurados.
Cliquemos em connect-default
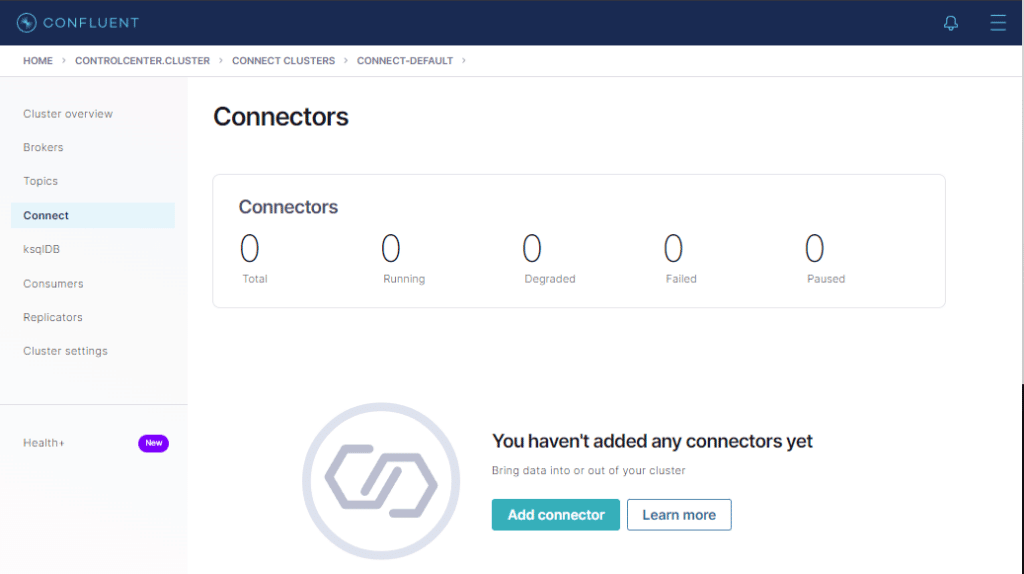
Cliquemos no botão Add connector
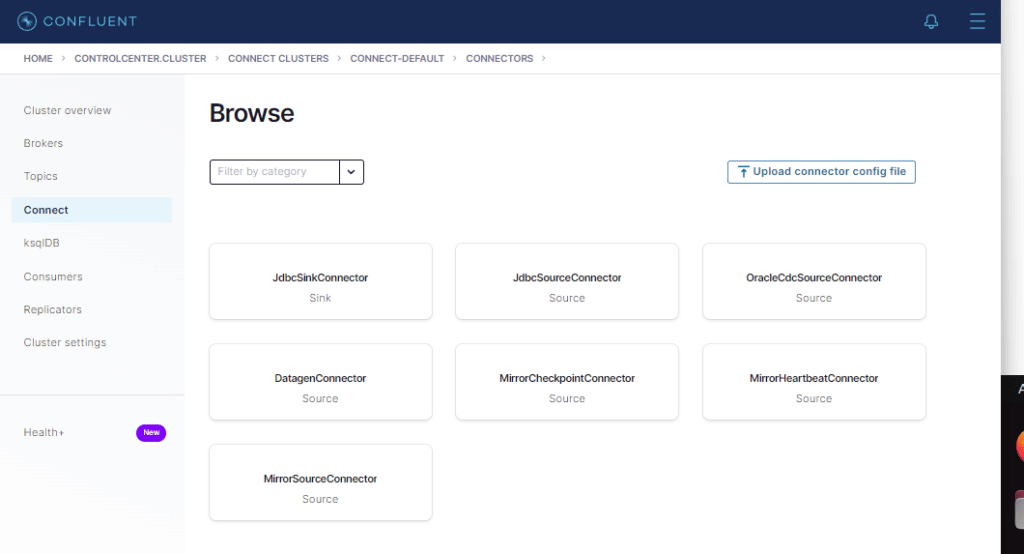
Aqui está a lista de todos os conectores disponíveis. Inclusive os dois que instalamos no segundo artigo.
Cliquemos em upload connector config file e escolhamos o arquivo ConnOracleCDC.json
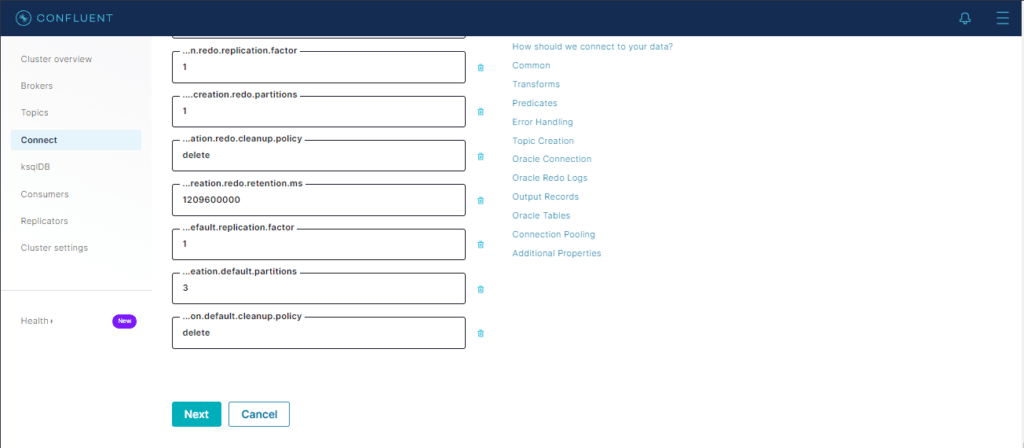
Todo o conteúdo do arquivo aparecerá de forma visual nos seus respectivos parâmetros.
Cliquemos no botão Next para que ele faça o parse do arquivo e o valide.
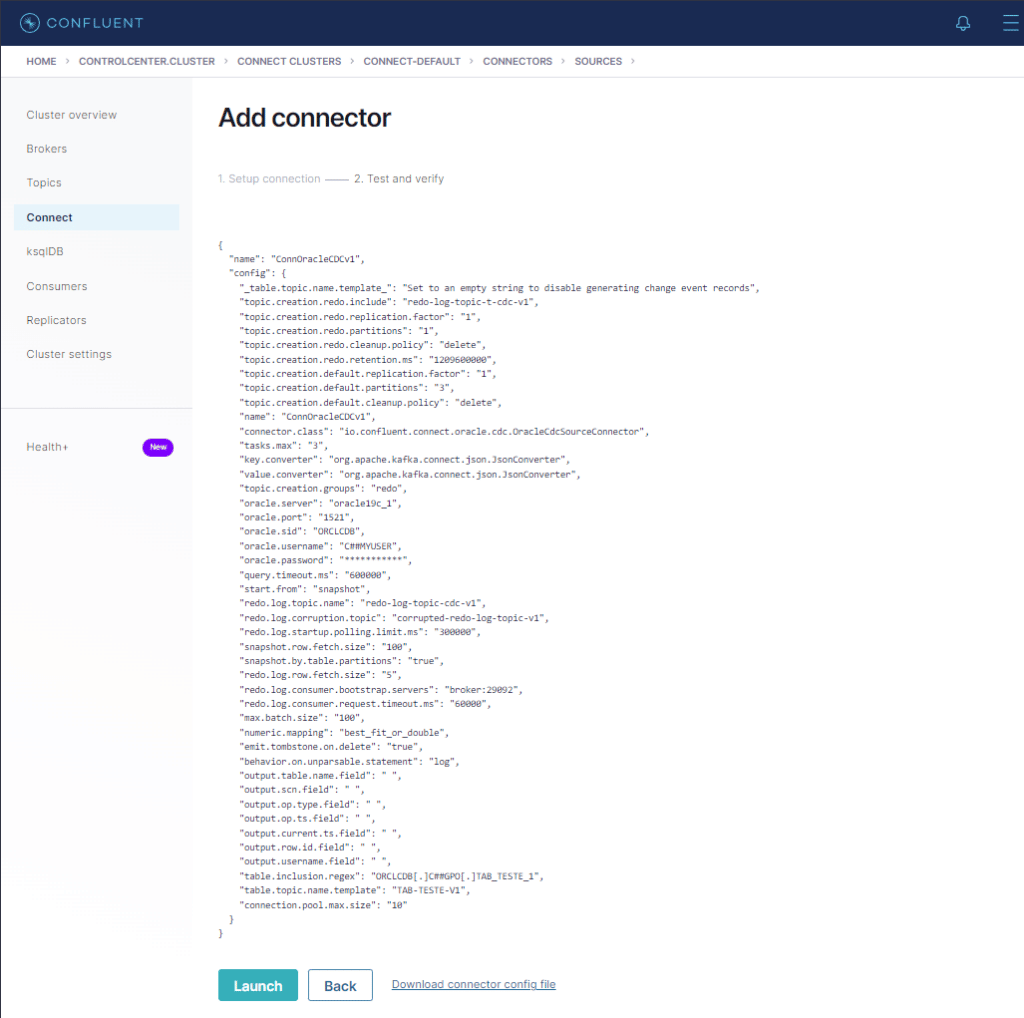
Se a tela acima for exibida, o conector está valido e já pode ser lançado. Cliquemos no botão Launch.
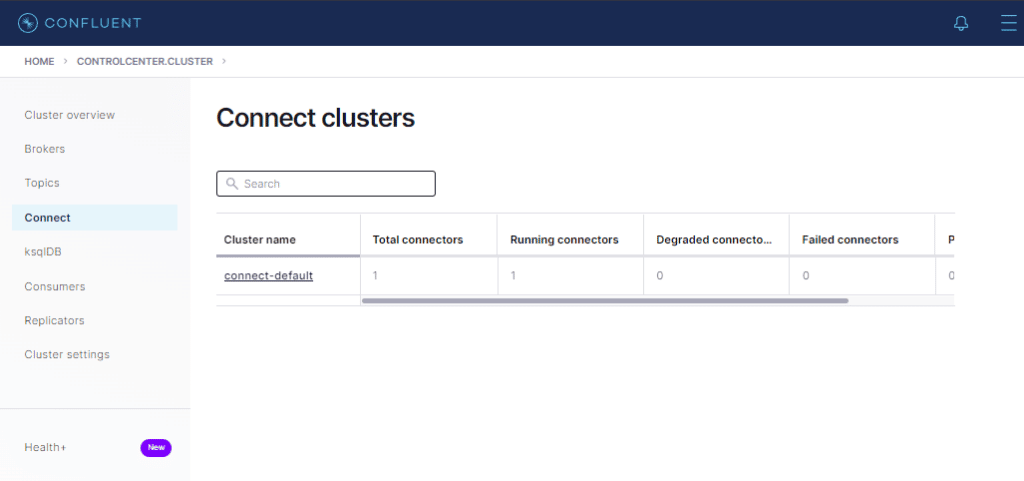
Veja que já há um conector configurado agora ! Cliquemos em connect-default.
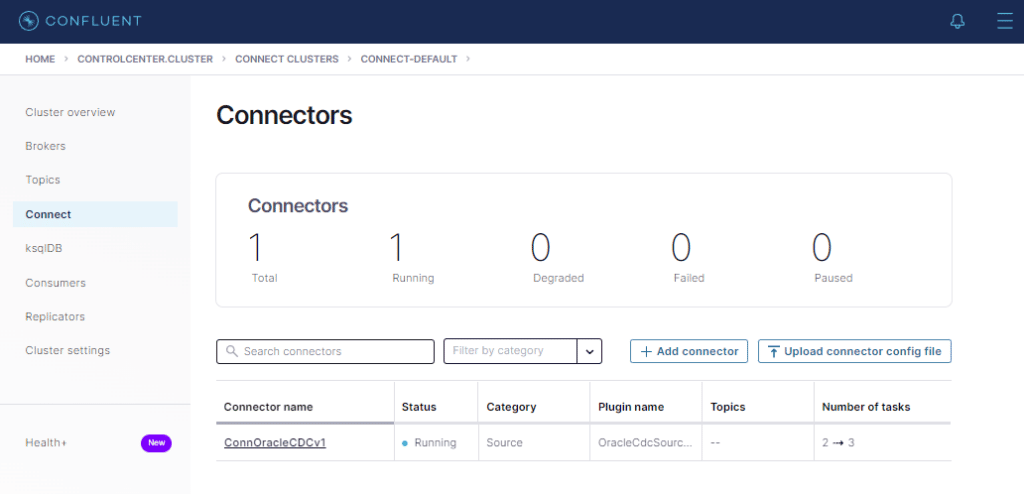
Conector executando sem erros ! 🙂
Agora cliquemos em ConnOracleCDC
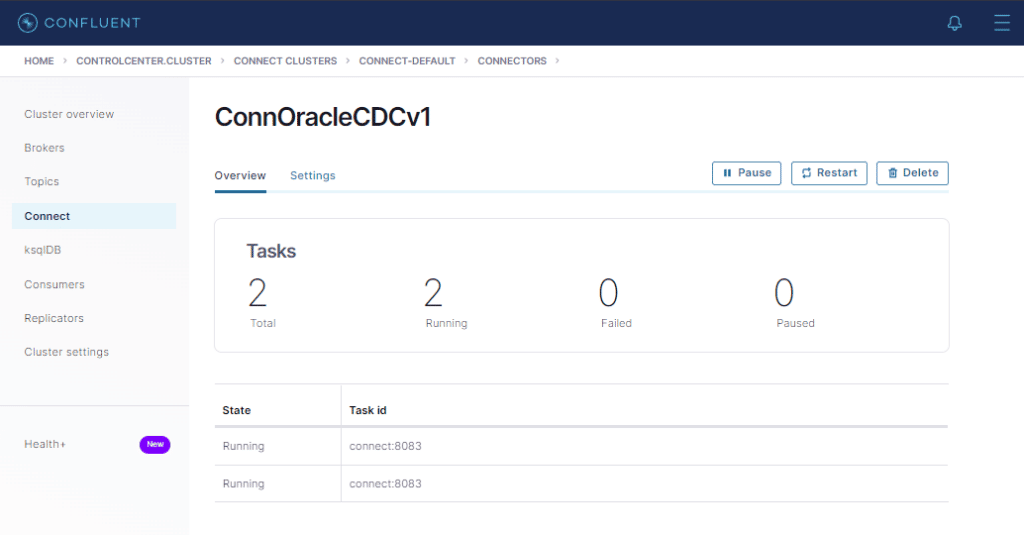
As duas tasks rodando sem erro ! 🙂
Agora vamos verificar se o tópico da tabela (TAB-TESTE-V1) foi criado. Cliquemos então na opção Topics a direita.
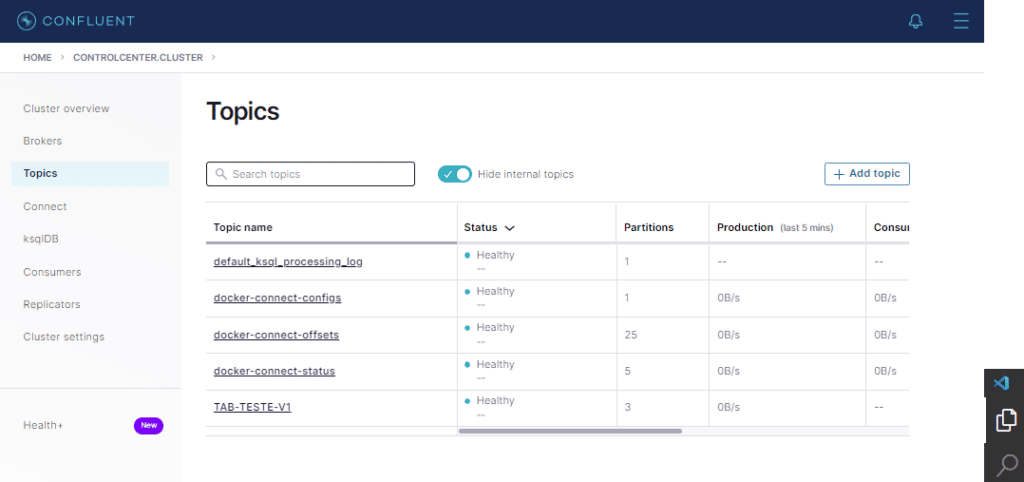
Perfeito ! Agora vamos lançar o conector Sink usando o mesmo procedimento que foi utilizado no conector CDC.

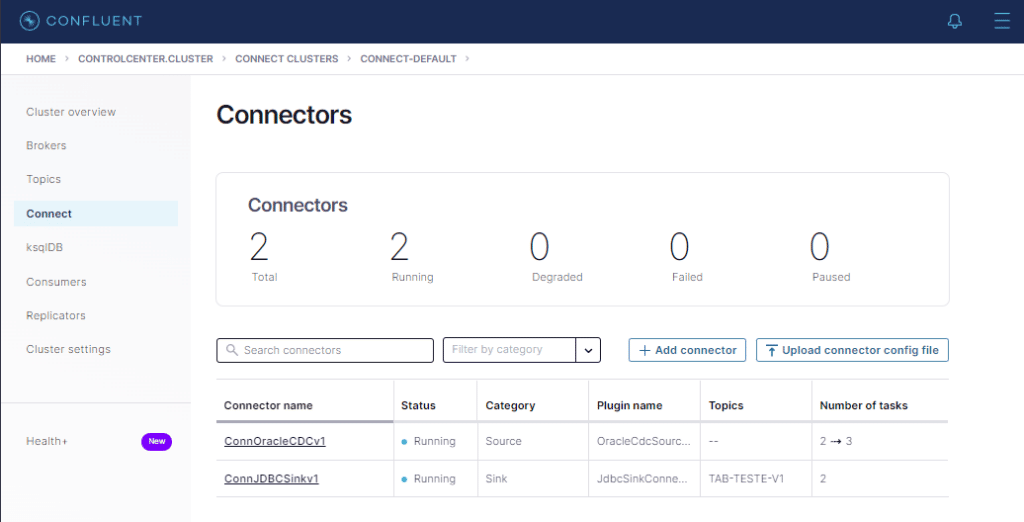
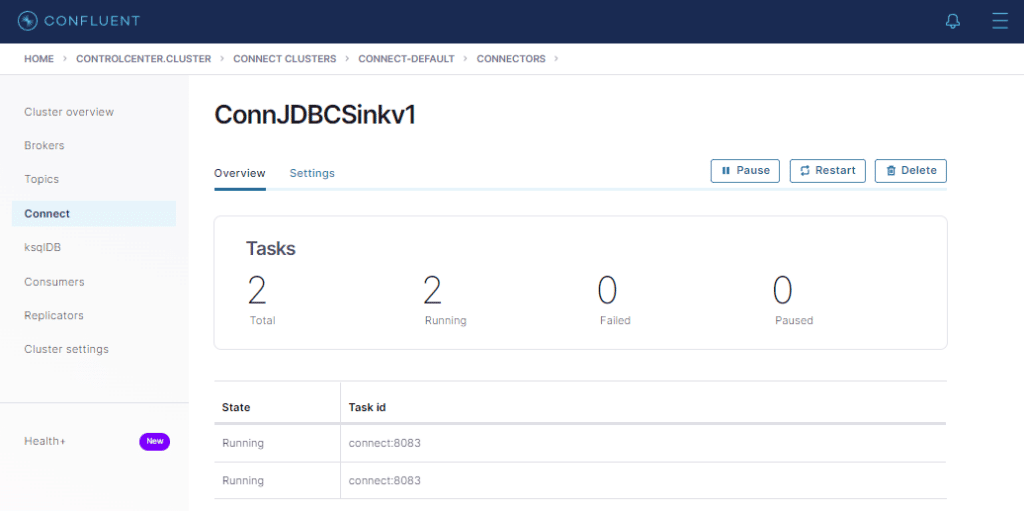
Conector Sink executando com sucesso !
Agora acessemos o banco oracle19c_2 com o usuário C#GPO e dê um SELECT na tabela.
SELECT * FROM tab_teste_1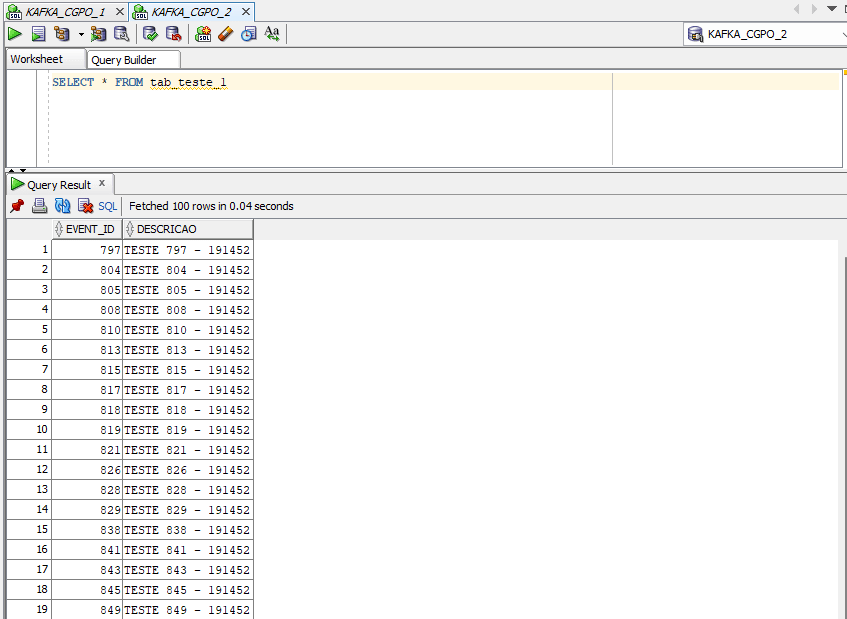
Snapshot da tabela concluído com sucesso ! 🙂
Vamos analisar o que fizemos até agora.
Apenas o tópico da tabela foi criado, e o de redo log não. O motivo para isso é que o conector Oracle CDC efetua o snapshot fazendo uma leitura full da tabela e insere direto no tópico.
Após terminar esse procedimento, ele marca o número do SCN e passa a fazer a leitura dos redo logs a partir desse ponto.
Isso pode ser um problema quando falamos de uma tabela com milhões de registros. Porém, para esses casos, há outras maneiras de se fazer a cópia dos dados e depois informar o SCN ao conector para que ele comece do ponto definido. Claro que não é o nosso caso !
Vamos agora forçar o conector a criar o tópico de redo log e efetuar a mudança na tabela de destino. Para isso, vou fazer um UPDATE no campo descrição em todos os 1000 registros no banco de origem (oracle19c_1).
UPDATE tab_teste_1
SET descricao = descricao || ' - ALT: ' || TO_CHAR(sysdate,'hh24miss')1,000 rows updated.Voltemos aos tópicos
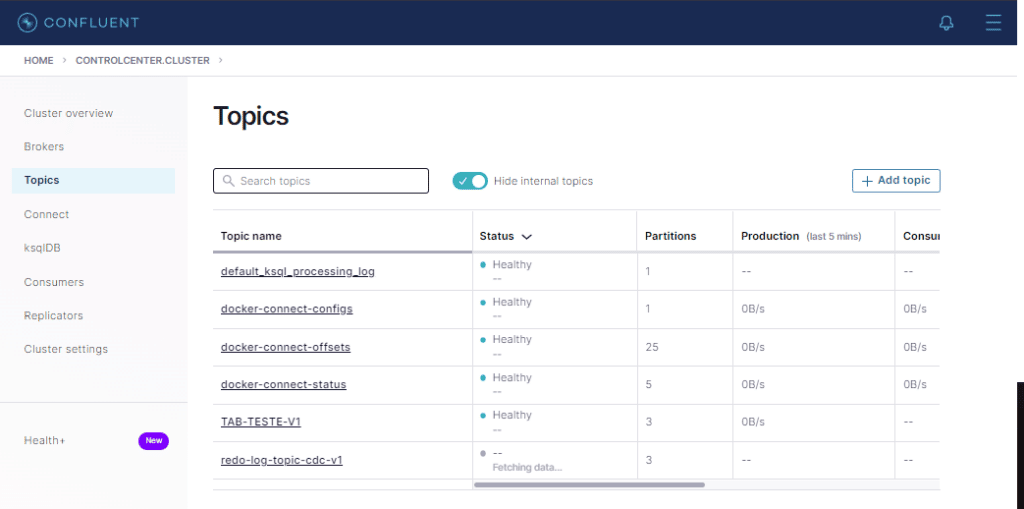
Olha lá o tópico do redo log ! 🙂
Antes de verificarmos os dados no banco destino, vou mostrar algo interessante. Clique no tópico redo-log-topic-cdc-v1.
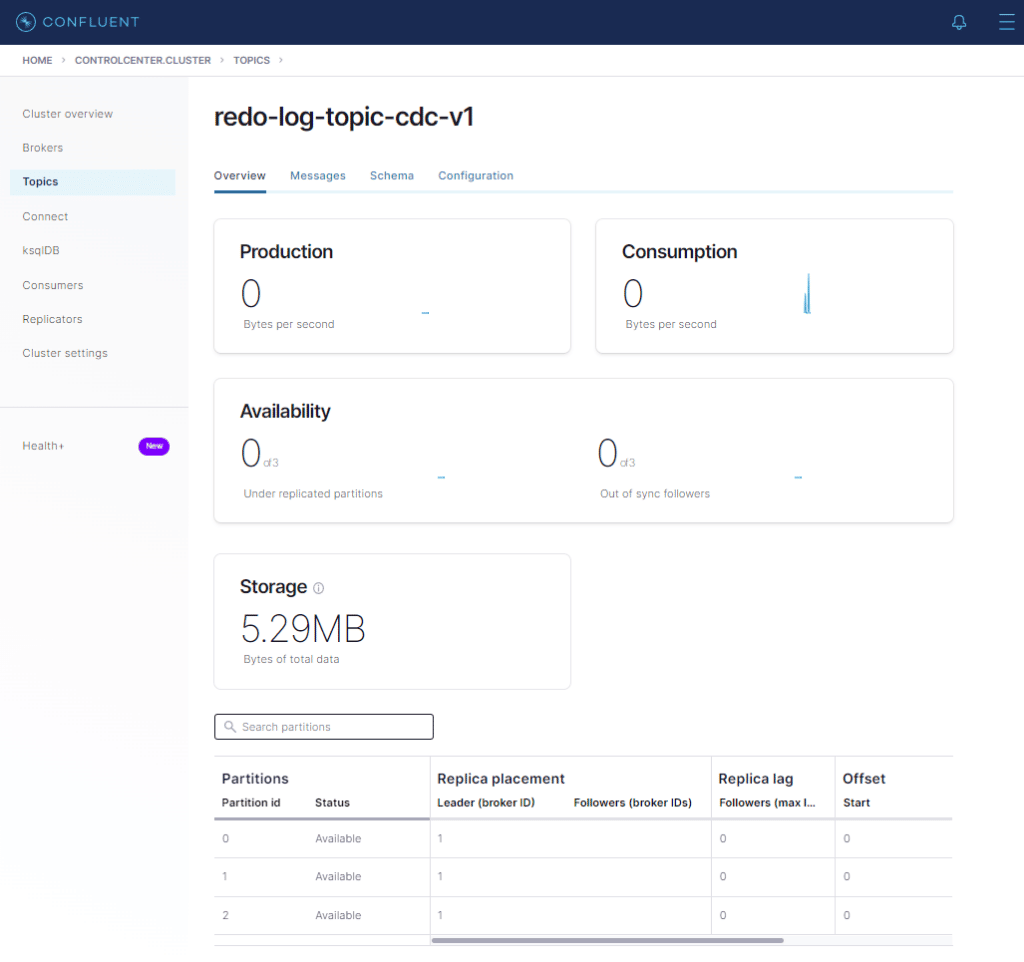
Cliquemos em Messages
Agora executemos novamente o mesmo UPDATE
UPDATE tab_teste_1 SET descricao = descricao || ' - ALT: ' || TO_CHAR(sysdate,'hh24miss')Agora volte ao Control Center
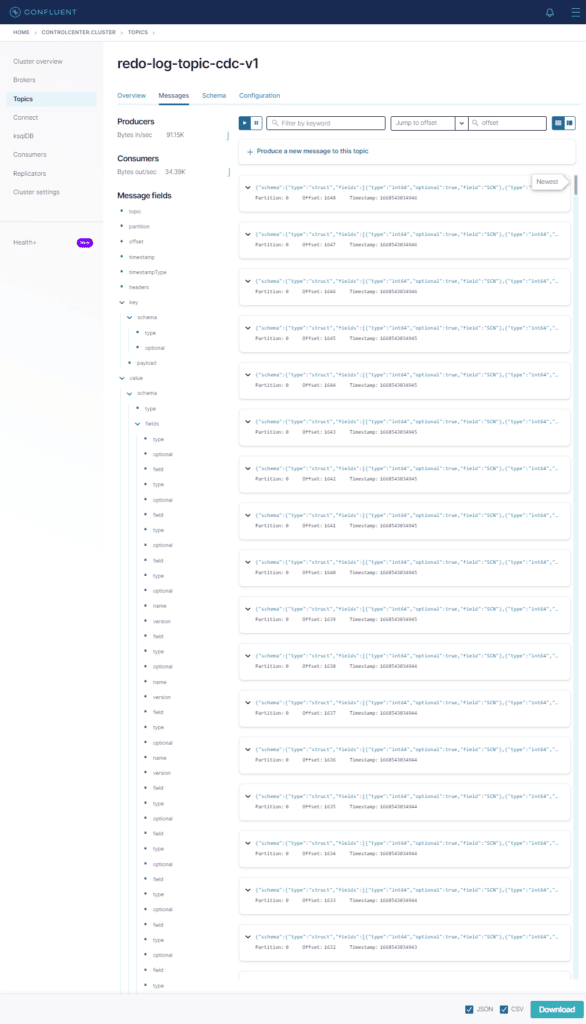
Olha aí as mensagens com os redo logs no tópico !
Vamos abrir uma e ver como é. Clique em uma das mensagens.
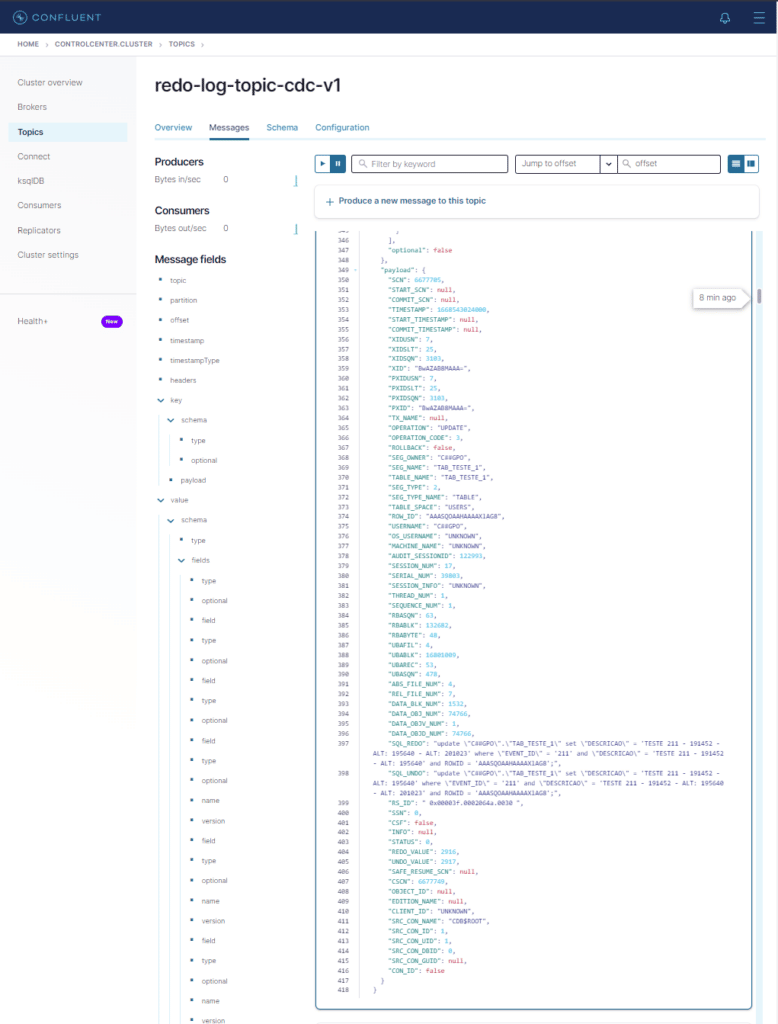
Toda a estutura do redo e undo está aí ! 🙂
Agora vamos ao banco destino (oracle19c_2) e vamos dar um SELECT na tabela.
SELECT * FROM tab_teste_1Olha aí os dados alterados !
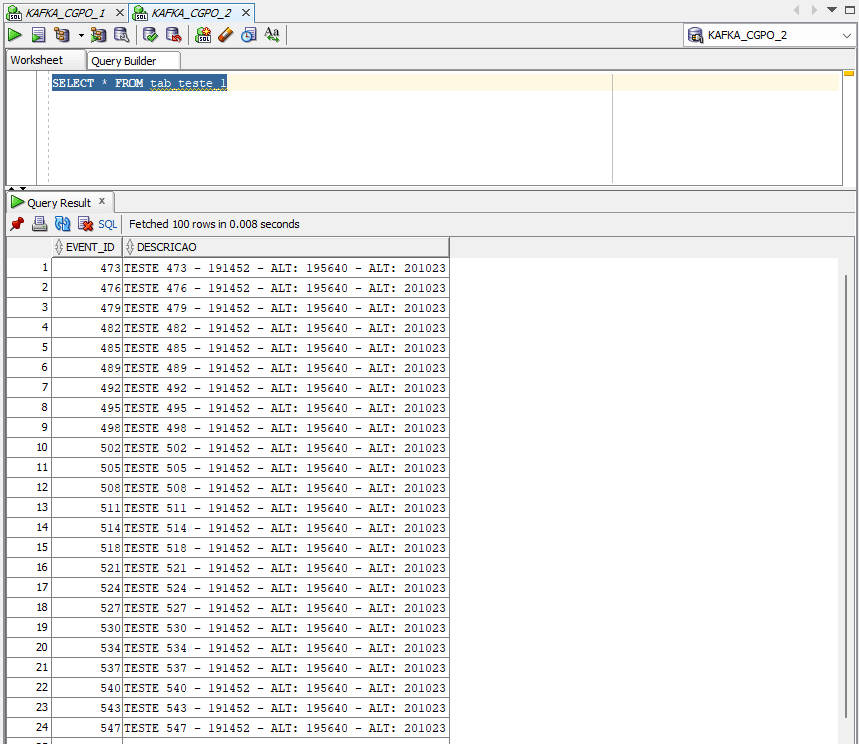
Vamos deletar o registro com o event_id 508 no banco origem (oracle19c_1)
DELETE tab_teste_1
WHERE event_id = 508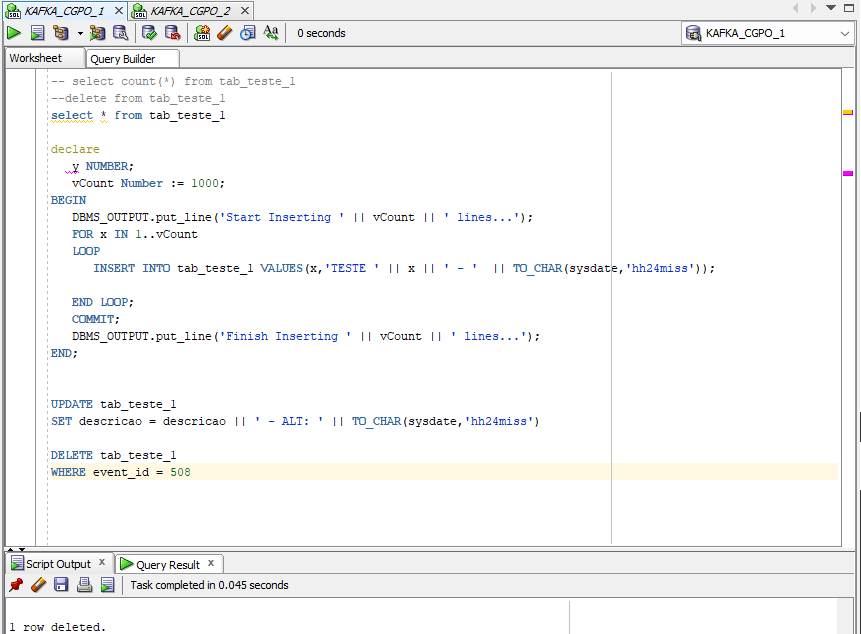
Agora vamos dar uma olhada no banco destino (oracle19c_2)
SELECT * FROM tab_teste_1
WHERE event_id = 508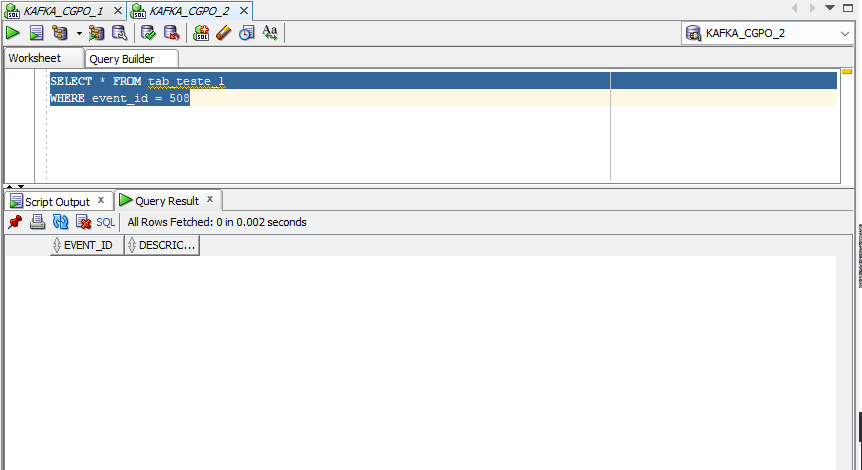
Replicação efetuada com sucesso ! 🙂
Espero que essa nossa caminhada pelos 5 artigos possam dar a você um panorama das capacidades do Kafka na plataforma da Confluent.
Leia a documentação, faça testes e divirta-se com os inúmeros parâmetros e possibilidades !
Caso tenha alguma dúvida, fique a vontade em comentar ou mesmo entrar em contato diretamente comigo ! 🙂
Uma última dica que dou é, enquanto executa as operações, dê uma olhada nos logs dos contêineres connect e broker. Você verá coisas bem interessantes sobre o funcionamento da plataforma !
Um grande abraço !
Referências
Cara, que publicações sensacionais! Obrigado por compartilhar esse conhecimento!!!
Boa tarde Ricardo !
Fico feliz que tenha gostado. Novas publicações virão.