

Coleta de estatísticas no Oracle – Parte I
Olá pessoal, hoje irei falar sobre a famosa coleta de estatística no Oracle. Esse artigo será dividido em várias partes para não ficar muito extenso e denso.
Cost Based Optimizer
O CBO (Cost Based Optimizer) foi criado no Oracle 7 para substituir o RBO (Rule Based Optimizer). Ele, a grosso modo, é o cérebro do Oracle.
Ele examina todos planos de execução possíveis para um SQL e pego aquele que possuir menor custo (na teoria) onde o custo é representado pela estimativa de recursos usados para um determinado plano de execução.
Agora você deve estar pensando: “Bom, se ele é o responsável pelos planos de execuções das minhas querys, como ele define o que é melhor ou bom? De onde vem essas informações? É ai que chegamos ao objetivo deste artigo, coleta de estatísticas. É através das estatísticas dos objetos e de sistema que ele se baseia para montar os planos de execução.
Em outras palavras, quanto mais real as informações que ele tiver, melhor será um plano. Num exemplo simples, caso uma tabela possua 1.000.000 linhas e não possua estatísticas uma query que deveria utilizar um índice pode fazer um FTS (Full table scan).
O que é o Optimizer Statistics?
Nas documentações você encontrará muito o termo Optimizer Statistics, ele é usado para fazer referência as “estatísticas” do database.
O Optimizer Statistics nada mais é do que um conjunto de dados armazenados no dicionário de dados que descrevem o database e os seus objetos. As informações são usadas pelo CBO para escolher o melhor plano de execução para cada SQL. As estatísticas de tabelas são compostas pelo número de linhas, número de blocos e tamanho médio da linha. O custo de acesso para uma tabela é calculado usando o número de blocos em conjunto com o DB_FILE_MULTIBLOCK_READ_COUNT. A view ALL_TAB_COL_STATISTICS mostra o número de valores distintos assim como o valor mínimo e máximo em uma coluna.
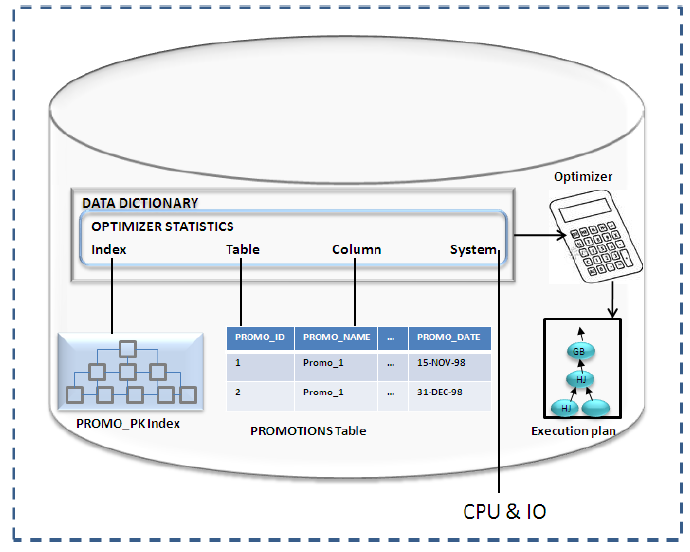
O optimizer usa a coluna de estatísticas em conjunto com as informações da tabela (número de linhas atual) para estimar o número de linhas que será retornado pelo SQL.
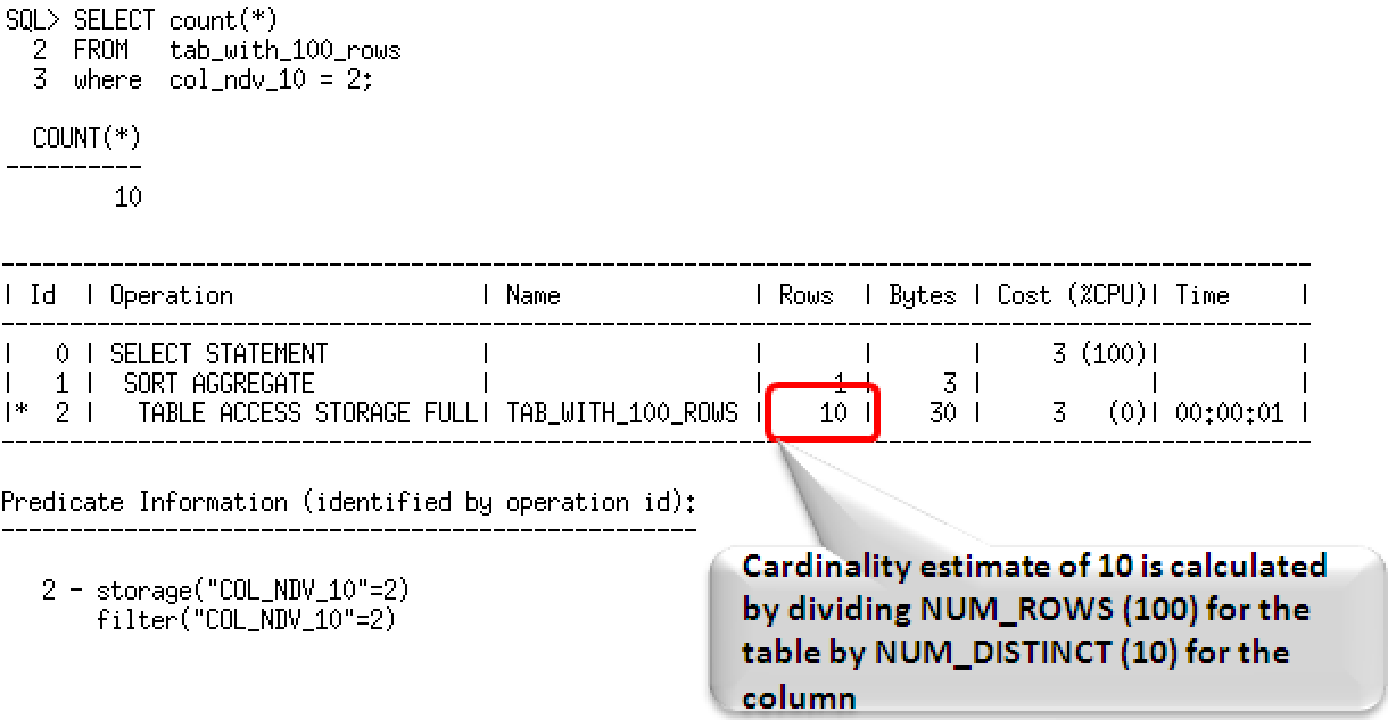
Por exemplo, se uma tabela possui 100 registros e o acesso na tabela possui um predicado com uma coluna de 10 valores distintos então o Optimizer, assumindo uma distribuição de dados uniforme, calcula uma estimativa da cardinalidade sendo o número de linhas na tabela dividido pelo número de valores distintos: 100/10=10.
Ok, legal! Vimos uma pequena parte da teoria e entendemos que as estatísticas são importantes para termos nossa noite de sono tranquila e ninguém nos ligar dizendo que o processamento diário está lento por conta de um plano ruim. Mas como eu sei se as estatísticas estão sendo coletadas? Se estão, estão sendo coletadas corretamente? Quando criamos o database existem jobs que são criados automaticamente pelo Oracle na própria scheduler que coletam essas informações, no 10g esse job era chamado GATHER_STATS_JOB, a partir do 11g esse job não existe mais e os jobs de estatística estão como tarefas automáticas de manutenção.
SQL> SELECT CLIENT_NAME, STATUS FROM DBA_AUTOTASK_CLIENT;
CLIENT_NAME STATUS
---------------------------------------------------------------- -------
auto optimizer stats collection ENABLED
auto space advisor ENABLED
sql tuning advisor ENABLEDPara desabilitar a coleta basta executar:
SQL> BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE (
CLIENT_NAME => 'AUTO OPTIMIZER STATS COLLECTION'
,OPERATION => NULL
,WINDOW_NAME => NULL
);
END;
/Para habilita basta executar:
SQL> BEGIN
DBMS_AUTO_TASK_ADMIN.ENABLE (
CLIENT_NAME => 'AUTO OPTIMIZER STATS COLLECTION'
,OPERATION => NULL
,WINDOW_NAME => NULL
);
END;
/Infelizmente eu não encontrei nenhuma informação sobre como a coleta é feita em si, nível de paralelismo, porcentagem de coleta, etc. Mas a coleta é sempre feita na janela de manutenção. Pessoalmente, eu não gosto dessa task e prefiro criar o meu próprio job para efetuar a coleta.
HISTOGRAMAS
Um histograma diz ao Optimizer como está a distribuição dos dados em uma coluna. O padrão é não existir histogramas nas colunas, isso faz com que o Optimizer assuma uma distribuição uniforme das linhas através dos valores distintos das colunas. O Optimizer calcula a cardinalidade de um predicado de igualdade dividindo o número de linhas pelo número de valores distintos em uma coluna. Se os dados distribuídos em uma coluna não são uniformes a cardinalidade estimada será incorreta. Para tentar refletir uma precisão maior em dados distribuídos não uniformemente um histograma é necessário na coluna. A presença desse histograma muda a formula que o Optimizer estima a cardinalidade e o habilita a gerar melhores planos de execução. Essas decisões são tomadas com base na SYS.COL_USAGE$ e na presença de dados desordenados.
SQL> desc SYS.COL_USAGE$
Name Null? Type
----------------------------------------- -------- ----------------------------
OBJ# NUMBER
INTCOL# NUMBER
EQUALITY_PREDS NUMBER
EQUIJOIN_PREDS NUMBER
NONEQUIJOIN_PREDS NUMBER
RANGE_PREDS NUMBER
LIKE_PREDS NUMBER
NULL_PREDS NUMBER
TIMESTAMP DATEExistem dois tipos de histogramas o de FREQUENCY e o de HEIGTH-BALANCED, ele baseia o tipo de histograma que será criado no número de valores distintos da coluna.
HISTOGRAMAS DE FREQUÊNCIA (FREQUENCY)
São criados quando os números de valores distintos em uma coluna são menores que 254.
Vamos ao exemplo abaixo:
O Oracle irá criar um FREQUENCY HISTOGRAM na coluna PROMO_CATEGORY_ID da tabela PROMOTIONS. No primeiro momento será selecionado o PROMO_CATEGORY_ID ordenado por ele mesmo, PROMO_CATEGORY_ID.
No segundo instante cada registro é designado para um bucket (balde).

Nesse momento teremos mais de 254 histogram buckets, nisso todos os buckets que possuem o mesmo valor são comprimidos e inseridos no bucket de maior valor, ou seja, buckets de 2 até 115 são compridos e inseridos no bucket 115, os buckets de 484 até 503 são comprimidos e inseridos no bucket 503 e assim por diante até o número de buckets ficarem iguais ao número de valores distintos da coluna.
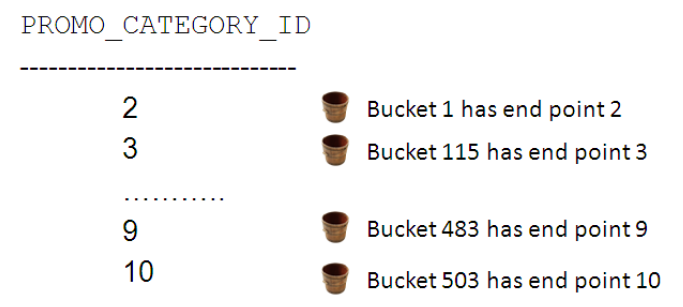
Agora o Optimizer calcula e determina a cardinalidade de predicados da coluna PROMO_CATEGORY_ID usando um FREQUENCY HISTOGRAM. Caso uma consulta procure pelo PROMO_CATEGORY_ID=10 o Optimizer precisa primeiro determinar quantos buckets no histograma possuem o valor 10. Encontrando o bucket que possui esse valor, bucket 503, e subtraindo esse valor pelo número do bucket anterior, no caso 483.
503 – 483 = 20
A cardinalidade estimada será calculada usando a formula:
(número de valores nos buckets / número de buckets) * NUM_ROWS
20 / 503 x 503 = 20
Então o número de linhas com o valor 10 na coluna PROMO_CATEGORY_ID é 20.
HEIGTH-BALANCED
São criados quando o número de valores distintos em uma coluna são maiores que 254. Os valores das colunas são divididos dentro dos buckets, cada bucket contém aproximadamente o mesmo número de linhas.
Vamos assumir que estamos criando um HEIGHT-BALANCED HISTOGRAM na coluna CUST_CITY_ID da tabela CUSTOMERS. Da mesma forma que é feito no FREQUENCY HISTOGRAM o primeiro passo é selecionar o CUST_CITY_ID ordenado por si mesmo. Após isso é verificado que existem 55.500 linhas na tabela CUSTOMERS. Tendo em vista que o número máximo de buckets é de 254 o Oracle precisa colocar 219 linhas em cada bucket ( 55.500 / 254 = 218,50…). O registro número 219 da coluna CUST_CITY_ID do primeiro passo ficará no primeiro bucket, nesse caso é o valor 51043. O registro número 434 ficará no segundo bucket e assim por diante até preencher os 254 buckets.
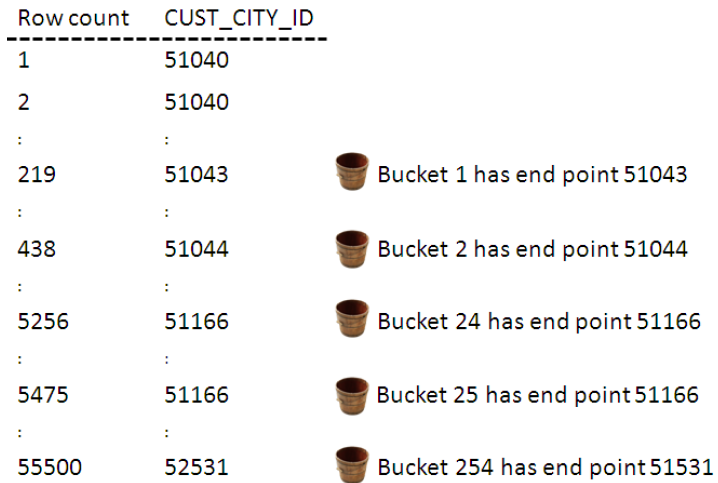
Depois de criar os buckets o Oracle verificar se o valor do primeiro bucket é menor da coluna, caso ele não seja um bucket 0 é adicionado ao histograma como o menor valor da coluna.
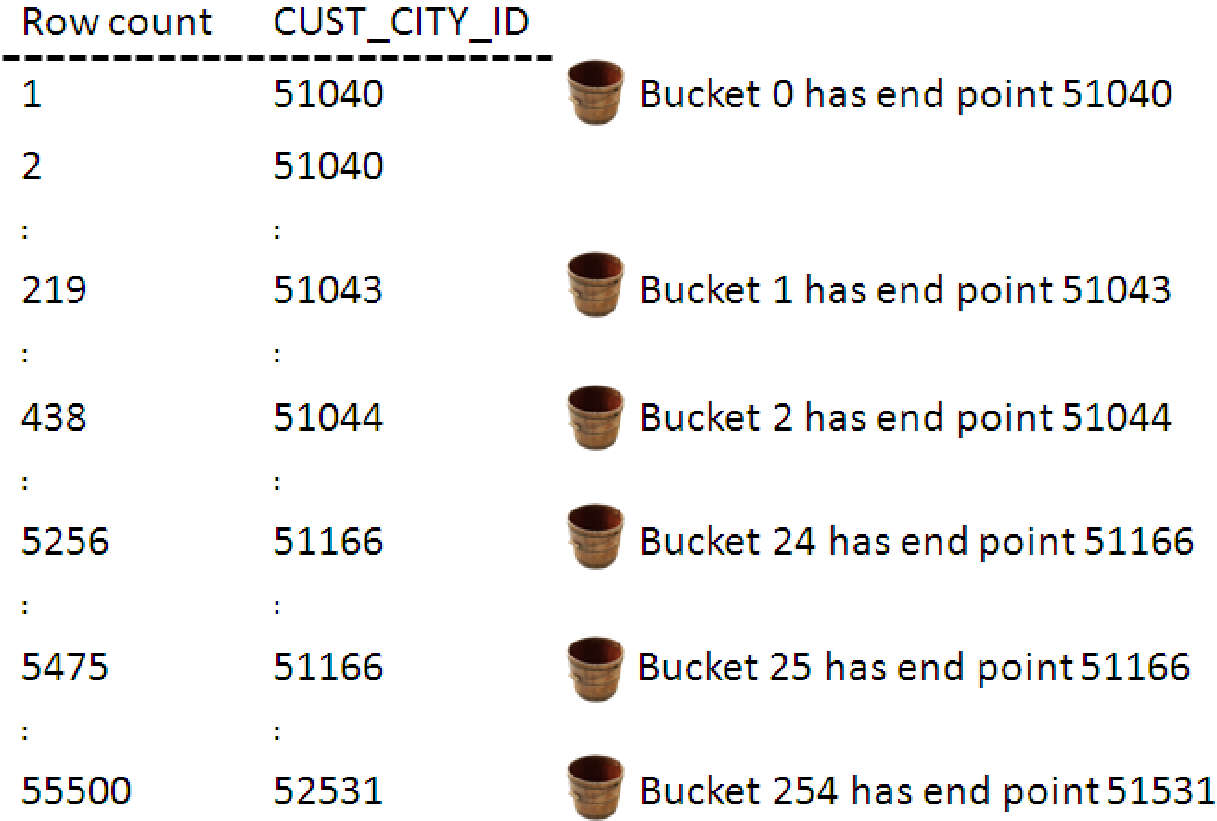
Assim como no FREQUENCY HISTOGRAM o passo final é comprimir o histograma e remover os buckets com valores duplicados. O valor 5116 é valor para o bucket 24 e 25 então o bucket 24 será comprimido dentro do bucket 25.
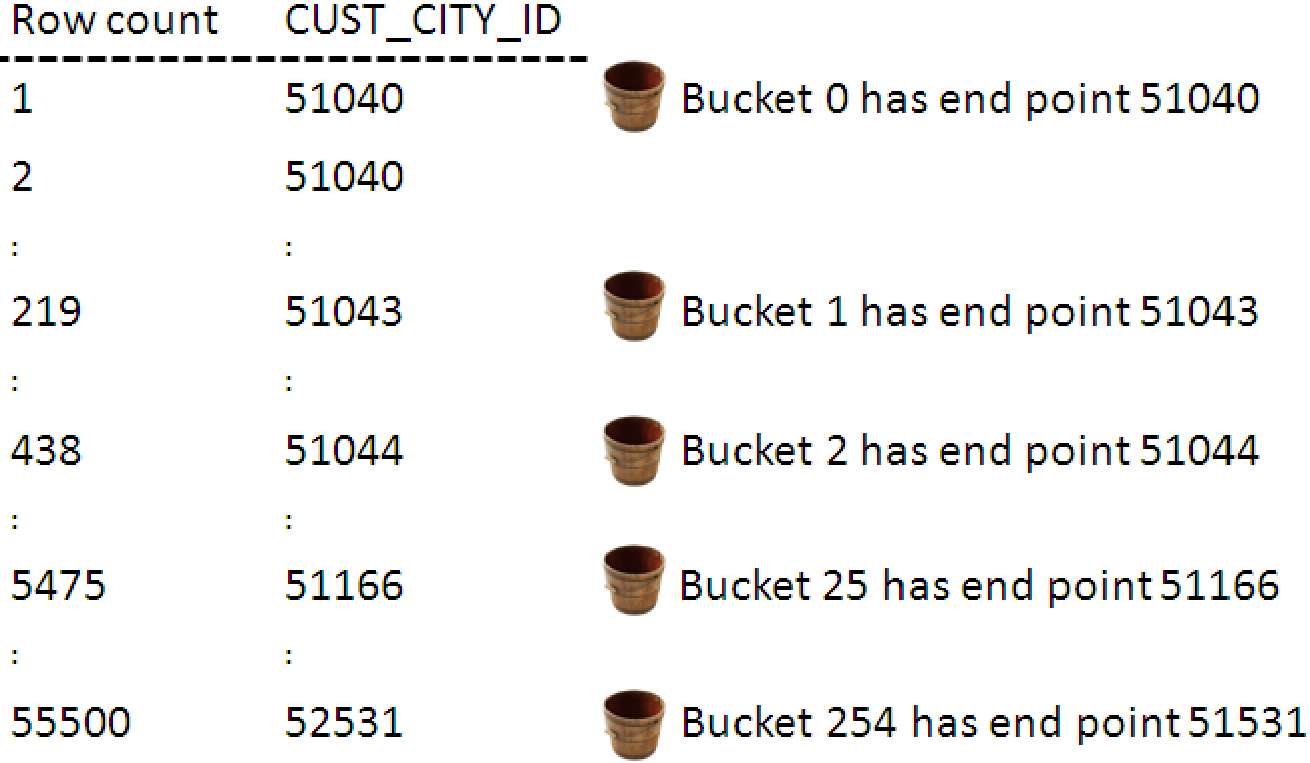
Agora o Optimizer calcula uma cardinalidade melhor para os predicados na coluna CUST_CITY_ID usando o HEIGHT-BALANCED HISTOGRAM. Por exemplo:
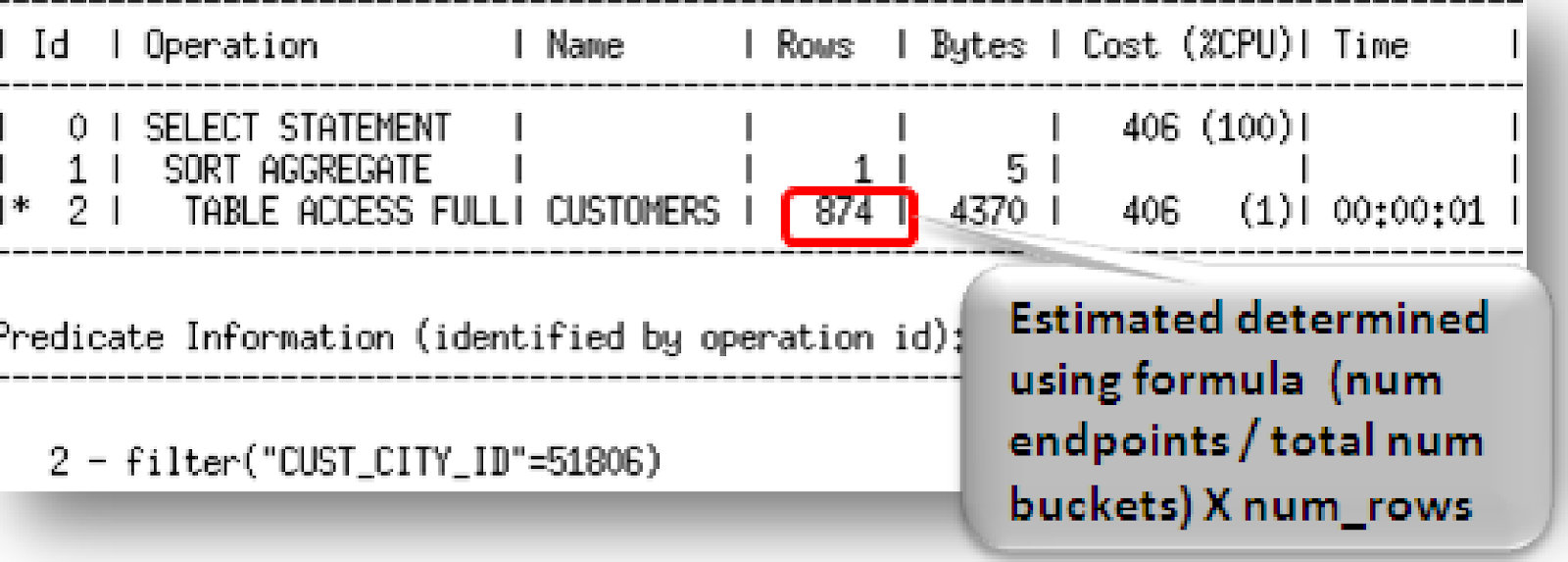
Se o valor para a coluna CUST_CITY_ID=51806 o optimizer irá verificar quantos buckets possuem o valor 51806. Nesse caso são os buckets 136, 137, 138 e 139 (essa informação vem da USER_HISTOGRAMS), o cálculo usado é o seguinte:
(Número de valores encontrados nos buckets / número total de buckets) * NUM_ROWS
4/254 X 55500 = 874
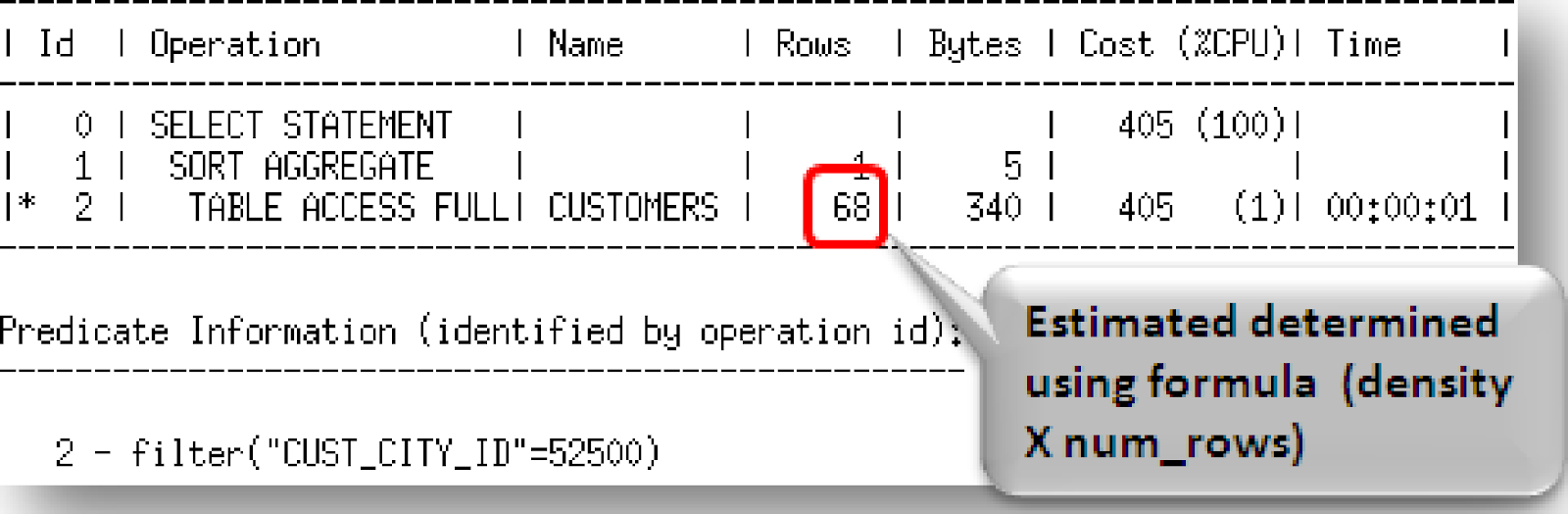
Entretanto, se o predicado fosse CUST_CITY_ID=52500, que é um valor que não existe (ou valores que possuem um bucket) para nenhum bucket então o Optimizer usa uma formula diferente.
DENSIDADE (DENSITY) x número de linhas na tabela
Onde a densidade é calculada no momento da optimização usando uma formula interna baseada nas informações do histograma. O valor da DENSIDADE que é visto na USER_TAB_COL_STATISTICS não é usado pelo Optimizer nas versões 10.2.0.4 para frente. Esse valor é apenas guardado para compatibilidade com versões anteriores. Além disso, se o parâmetro OPTIMIZER_FEATURES_ENABLE é setado para uma versão mais nova que o 10.2.0.4 o valor da DENSIDADE do dicionário de dados será usado.
EXTENDED STATISTICS
No 11g foram introduzidos dois tipos de estatisticas, column group e expression.
COLUMN GROUPS
Em modelos relacionais é muito comum encontrarmos tabelas auto relacionáveis, por exemplo: Tabela CUSTOMERS possui a coluna COUNTRY_ID que é relacionada a coluna CUST_STATE_PROVINCE. Usando a coleta básica de estatísticas o Optimizer não sabe dessa relação “do mundo real” entre as colunas e pode gerar uma cardinalidade errada dos dados. Para evitar isso podemos criar estatísticas por grupo de colunas (column groups). A procedure para esse procedimento é a DBMS_STATS.CREATE_EXTENDED_STATS.
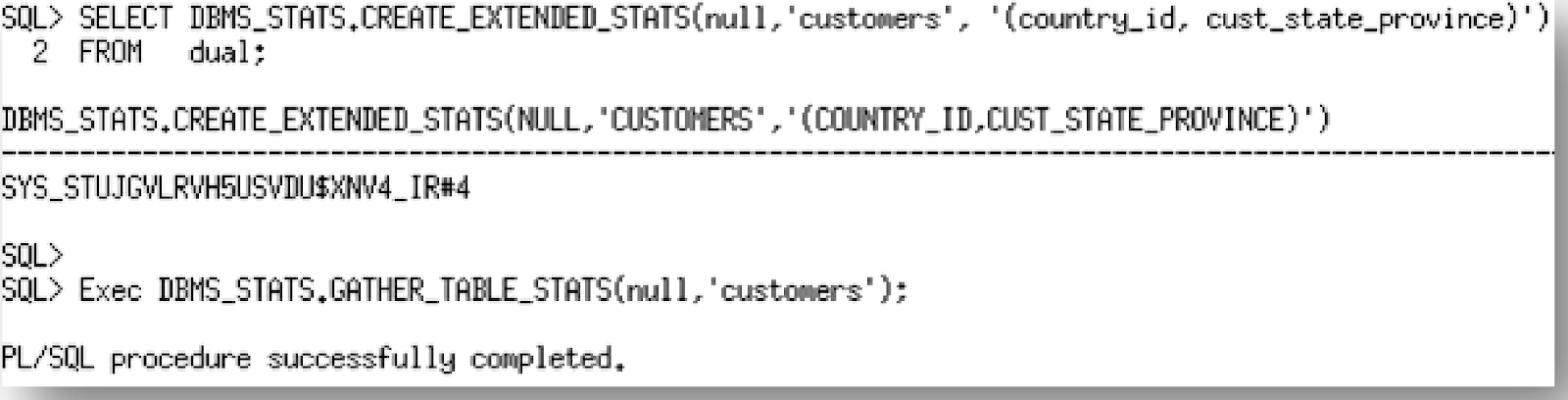
Após criar as estatísticas para o grupo de colunas você verá uma nova linha inserida na USER_TAB_COL_STATISTICS:
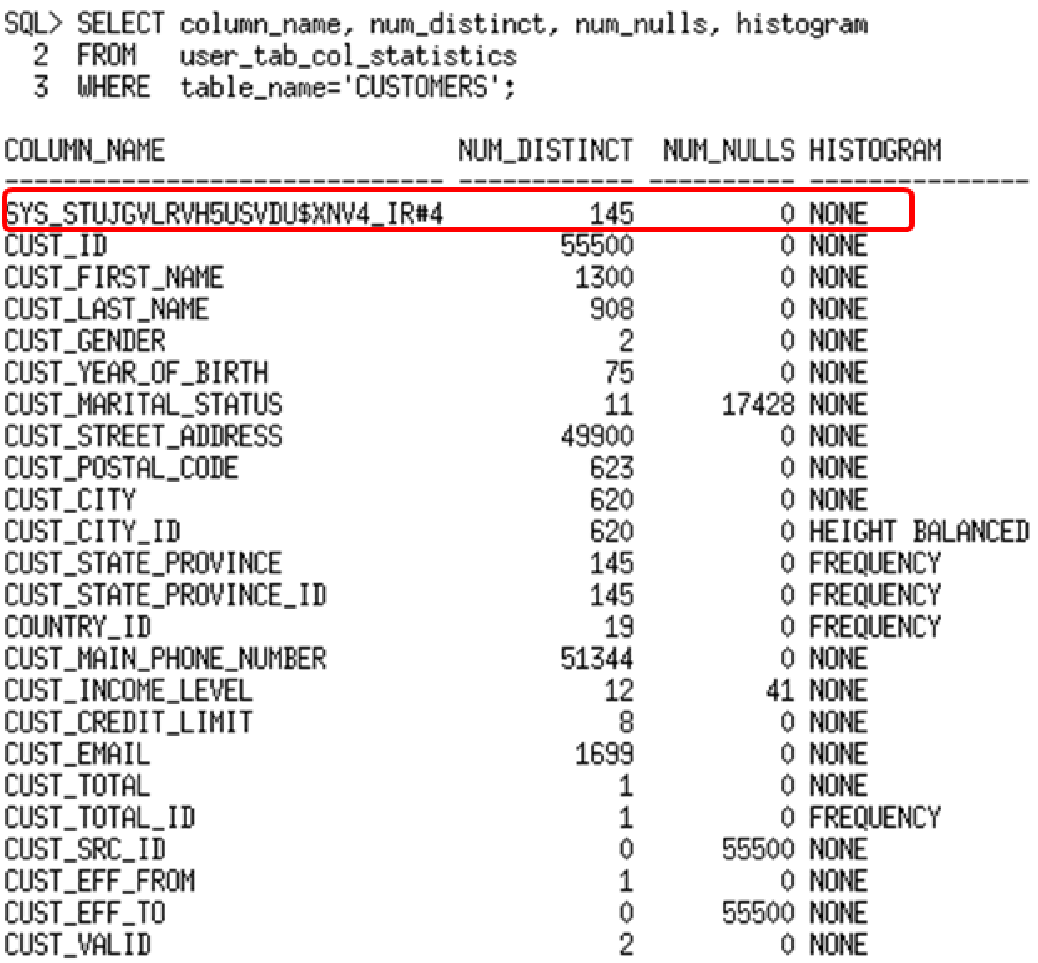
Para verificar se existem mais column group statistics basta executar o select abaixo:

EXPRESSION STATISTICS
Também é possível criar estatisticas para expressões com funções, por exemplo: Se uma coluna CUST_LAST_NAME é sempre usada com uma function UPPER, podemos criar a seguinte coleta:

Agora o Oracle já tem informações dos dados em UPPER case para a coluna em questão.
Porém extended statistics serão usadas apenas quando os predicados na clausula where possuem igualdade ou in-lists. Eles não serão usados quando existem histogramas nas colunas subjacentes ou não exista nenhum histograma na column group.
INDEX STATISTICS
As estatísticas dos índices fornecem informações sobre o número distinto de valores no índice, o nível dele (blevel), número de folhas de blocos (leaf blocks) no índice e o clustering factor. Essa informações são usadas com outras estatísticas para determinar o custo de acesso ao índice. O Optimizer irá usar o b-level, leaf_blocks e número de linhas da tabela para determinar o custo de um index range scan (quando todos os valores do comando SQL estão na no topo do índice).
GATHERING STATISTICS
Como todos sabem a coleta de estatísticas é primordial para o banco de dados. O jeito correto de se coletar estatísticas é com a package DBMS_STATS e não com o ANALYZE (apesar do ANALYZE ainda ser usado para validar e listar chained rows), esse comando já está obsoleto e não deve ser mais utilizado. Por que? Bom segundo a Oracle:
“Do not use the COMPUTE and ESTIMATE clauses of ANALYZE to collect optimizer statistics. These clauses are supported for backward compatibility. Instead, use the DBMS_STATS package, which lets you collect statistics in parallel, collect global statistics for partitioned objects, and fine tune your statistics collection in other ways. The cost-based optimizer, which depends upon statistics, will eventually use only statistics that have been collected by DBMS_STATS. You must use the ANALYZE statement (rather than DBMS_STATS) for statistics collection not related to the cost-based optimizer, to use the VALIDATE or LIST CHAINED ROWS clauses and to collect information on freelist block”.
A DBMS_STATS possui cerca de 50 diferentes opções para coletar e gerenciar estatísticas, mas o principal método é usado pelas procedures GATHER_*_STATS. É possível coletar estatísticas do database, dicionário de dados, de sistema, tabelas, colunas, partições e índices. Para isso, você precisa ser owner do objeto ou ter o grant de ANALYZE ANY ou role de DBA.
No próximo artigo veremos como coletar estatísticas e seus parâmetros opcionais e obrigatórios.
Leia a segunda parte do artigo: