

Kafka, Confluent Platform e Apache Flink: Uma combinação perfeita !
Olá pessoal!
É um prazer estar aqui novamente ! Hoje, trago para vocês um tema fascinante: a integração entre Kafka, Confluent Platform e Apache Flink. Vamos explorar juntos como essas ferramentas revolucionam o universo do streaming de dados e do processamento em tempo real.
Este texto inaugura uma série especial. Na edição de hoje, vamos mergulhar nos conceitos fundamentais dessas tecnologias e guiar vocês pelos primeiros passos da instalação. Preparados ? Vamos nessa !
Kafka
O Apache Kafka é uma plataforma de streaming distribuída e open-source que permite a publicação, subscrição, armazenamento e processamento de fluxos de registros em tempo real. Desenvolvido inicialmente pelo LinkedIn, Kafka é projetado para lidar com dados de várias fontes e entregá-los a diversos clientes. Ele é conhecido por sua alta capacidade e baixa latência, sendo ideal para cenários que exigem tratamento de dados em tempo real. Além disso, Kafka suporta integrações distribuídas, APIs e containers, facilitando o desenvolvimento de aplicações nativas em nuvem e conectadas. Sua arquitetura robusta e escalável o torna uma escolha popular para empresas que gerenciam grandes volumes de dados e buscam soluções de integração ágil.
Confluent Platform
A Confluent Platform é uma plataforma de streaming de dados em tempo real que amplia as capacidades do Apache Kafka. Desenvolvida pelos criadores originais do Kafka, ela oferece uma solução empresarial pronta para uso, com recursos avançados projetados para acelerar o desenvolvimento de aplicações e a conectividade. A plataforma permite transformações por meio de processamento de fluxo, simplifica operações empresariais em escala e atende a requisitos arquitetônicos rigorosos. Além disso, a Confluent Platform facilita a conexão de fontes de dados ao Kafka, a construção de aplicações de streaming e a gestão segura, monitorada e eficiente da infraestrutura Kafka. Ela é conhecida por sua escalabilidade, confiabilidade e segurança, ajudando as empresas a criar pipelines de dados em tempo real e integrar fluxos de dados de todas as fontes em um único sistema central de processamento de eventos.
Para os entusiastas que desejam mergulhar ainda mais fundo no universo da Confluent Platform e Kafka, tenho uma dica de ouro ! Não deixem de conferir a minha série dedicada à replicação de dados no banco de dados Oracle. Vamos desvendar juntos como o Kafka e o CDC podem transformar a maneira como você lida com seus dados.
É uma jornada repleta de insights e técnicas que vão elevar seu conhecimento a outro nível. Então, se você está buscando dominar essas ferramentas poderosas, essa série é para você !
- Replicação de dados com Kafka e Oracle CDC: Parte I – Primeiros Passos
- Replicando dados com Kafka e Oracle CDC – Parte II (Confluent Platform)
- Replicando dados com Kafka e Oracle CDC – Parte III (Conectores)
- Replicando dados com Kafka e Oracle CDC – Parte IV (Preparando o banco de dados)
- Replicando dados com Kafka e Oracle CDC – Parte V (Replicando dados)
- Conector Oracle CDC Kafka: Solução para replicação de campos do tipo Date com Time Portion
Apache Flink
O Apache Flink é uma estrutura e mecanismo de processamento distribuído para cálculos com estado em fluxos de dados ilimitados e limitados. Projetado para operar em ambientes de cluster comuns, o Flink executa cálculos em velocidade na memória e em qualquer escala. Ele suporta processamento de fluxo de alto throughput e baixa latência, e é capaz de executar programas data-flow arbitrários com paralelismo de dados e pipelines. O Flink é conhecido por sua tolerância a falhas, gerenciamento avançado de estado e semântica de processamento de tempo de evento. Ele não fornece um sistema de armazenamento de dados, mas oferece conectores para sistemas como AWS Kinesis, Apache Kafka, HDFS, Apache Cassandra e Elasticsearch.
Criando o nosso ambiente para estudos
Com as introduções devidamente realizadas, é hora de colocar a mão na massa e configurar o ambiente ! Vou guiar vocês pelo processo de instalação daquele que será nosso laboratório de diversão e aprendizado. Se você ja for um expert e sabe montar seu próprio lab, sinta-se à vontade para avançar. A escolha é sua !
Para montar nossa base de operações, vamos precisar de:
- VirtualBox: nosso aplicativo para criar e gerenciar máquinas virtuais.
- Ubuntu Desktop 24 LTS: o sistema operacional que vai dar vida ao nosso laboratório.
- Docker: o maestro dos containers, facilitando a criação e gestão de ambientes isolados.
- Portainer: a ferramenta que vai nos ajudar a administrar nossos containers Docker.
- Confluent Platform 7.2: o coração do nosso sistema de streaming, pronto para pulsar dados em tempo real.
- Flink: o cérebro analítico, processando e transformando dados com uma agilidade impressionante.
Virtualbox
O Oracle VirtualBox é um software de virtualização de código aberto desenvolvido pela Oracle. Ele permite criar e gerenciar máquinas virtuais (VMs), que são emulações de computadores completos, incluindo sistemas operacionais e aplicativos, dentro de um computador físico. Com o VirtualBox, é possível rodar múltiplos sistemas operacionais simultaneamente, facilitando o teste de softwares e a execução de aplicações em diferentes ambientes sem a necessidade de dual boot. É uma ferramenta valiosa para desenvolvedores e profissionais de TI, oferecendo flexibilidade e eficiência na gestão de recursos de hardware e software,
Para baixar o Virtualbox, CLIQUE AQUI !
Não conhece bem o Virtualbox ? Abaixo alguns cursos GRATUITOS que irão ajudá-lo:
- Virtualização no Oracle VirtualBox – Básico a Avançado
- Crie seu Ambiente de Laboratório com VirtualBox
Ubuntu
O Ubuntu Linux é uma distribuição de sistema operacional baseada em Linux, conhecida por sua facilidade de uso e suporte abrangente. Desenvolvido pela Canonical Ltd., o Ubuntu é gratuito e de código aberto, permitindo que os usuários modifiquem e distribuam o software como desejarem. Ele é adequado tanto para computadores pessoais quanto para servidores, e é altamente personalizável com uma grande comunidade de usuários e desenvolvedores. O Ubuntu se destaca por sua segurança robusta e atualizações regulares, tornando-o uma escolha popular para usuários de todos os níveis de habilidade Essas qualidades fazem do Ubuntu uma esolha perfeita para iniciantes.
Para baixar o Ubuntu, CLIQUE AQUI !
Se preferir, pode utilizar o guia de instalação do Ubuntu no Virtualbox que publiquei há algum tempo atrás. Nesse guia ele utiliza a versão 22. Porém, os procedimentos são os mesmos para o 24.
Caso queira aprender mais sobre o Ubuntu, abaixo um curso GRATUITO:
Docker
O Docker é uma plataforma de conteinerização open source que facilita a criação, implantação e gerenciamento de aplicações em containers Linux. Os containers permitem que as aplicações sejam executadas em diferentes ambientes de forma isolada e eficiente. Comparado às máquinas virtuais, o Docker é mais leve e rápido, pois compartilha o sistema operacional do host, reduzindo o uso de recursos. É amplamente utilizado para garantir a portabilidade e a consistência das aplicações, independentemente do ambiente de execução.
Portainer
O Portainer é uma interface gráfica de usuário (GUI) que simplifica o gerenciamento de contêineres Docker. Ele permite aos usuários administrar imagens, redes e volumes Docker, além de iniciar, parar e monitorar contêineres com facilidade. Compatível com ambientes Docker locais e remotos, o Portainer é ideal para quem busca uma gestão mais intuitiva sem depender da linha de comando. Ele também suporta o Docker Swarm, oferecendo uma solução robusta para orquestração de contêineres
Para instalar o Docker e o Portainer, você pode utilizar o guia abaixo:
Caso queira aprender mais sobre Docker, abaixo alguns cursos GRATUITOS:
- Docker Essentials: Aprenda Docker GRATUITAMENTE e domine a tecnologia dos containers
- Tutorial Docker para Iniciantes – Um curso completo de DevOps sobre como executar aplicativos em contêineres
- Introdução a Docker Containers (Hands On)
- Docker Container Images para Iniciantes
Com isso finalizamos a montagem de nosso ambiente !
Instalando a Confluent Platform e o Apache flink
Com nosso ambiente devidamente preparado, é chegado o momento de proceder com a instalação da Confluent Platform e do Apache Flink. Esta etapa, vocês verão, é surpreendentemente simples !
A Confluent oferece em seu repositório no GitHub uma variedade de ambientes já configurados, disponíveis para implementação através de Docker, Kubernetes ou até mesmo para instalação independente.
Optaremos por utilizar o arquivo YAML do Docker Compose que inclui a Confluent Platform e o Apache Flink. Para tanto, basta copiar o código que será apresentado a seguir e salvá-lo como docker-compose.yml. Sigamos adiante.
---
services:
broker:
image: confluentinc/cp-server:7.5.1
hostname: broker
container_name: broker
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092'
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: 'broker:9092'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@broker:29093'
KAFKA_LISTENERS: 'PLAINTEXT://broker:29092,CONTROLLER://broker:29093,PLAINTEXT_HOST://0.0.0.0:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
# Replace CLUSTER_ID with a unique base64 UUID using "bin/kafka-storage.sh random-uuid"
# See https://docs.confluent.io/kafka/operations-tools/kafka-tools.html#kafka-storage-sh
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qk'
schema-registry:
image: confluentinc/cp-schema-registry:7.5.1
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
connect:
image: cnfldemos/cp-server-connect-datagen:0.6.2-7.5.0
hostname: connect
container_name: connect
depends_on:
- broker
- schema-registry
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:29092'
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
# CLASSPATH required due to CC-2422
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-7.5.0.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components"
CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR
control-center:
image: confluentinc/cp-enterprise-control-center:7.5.1
hostname: control-center
container_name: control-center
depends_on:
- broker
- schema-registry
- connect
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_CONNECT_CONNECT-DEFAULT_CLUSTER: 'connect:8083'
CONTROL_CENTER_CONNECT_HEALTHCHECK_ENDPOINT: '/connectors'
CONTROL_CENTER_KSQL_KSQLDB1_URL: "http://ksqldb-server:8088"
CONTROL_CENTER_KSQL_KSQLDB1_ADVERTISED_URL: "http://localhost:8088"
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
ksqldb-server:
image: confluentinc/cp-ksqldb-server:7.5.1
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
- connect
ports:
- "8088:8088"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_BOOTSTRAP_SERVERS: "broker:29092"
KSQL_HOST_NAME: ksqldb-server
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
KSQL_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
KSQL_KSQL_CONNECT_URL: "http://connect:8083"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: 1
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: 'true'
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: 'true'
ksqldb-cli:
image: confluentinc/cp-ksqldb-cli:7.5.1
container_name: ksqldb-cli
depends_on:
- broker
- connect
- ksqldb-server
entrypoint: /bin/sh
tty: true
ksql-datagen:
image: confluentinc/ksqldb-examples:7.5.1
hostname: ksql-datagen
container_name: ksql-datagen
depends_on:
- ksqldb-server
- broker
- schema-registry
- connect
command: "bash -c 'echo Waiting for Kafka to be ready... && \
cub kafka-ready -b broker:29092 1 40 && \
echo Waiting for Confluent Schema Registry to be ready... && \
cub sr-ready schema-registry 8081 40 && \
echo Waiting a few seconds for topic creation to finish... && \
sleep 11 && \
tail -f /dev/null'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
STREAMS_BOOTSTRAP_SERVERS: broker:29092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
rest-proxy:
image: confluentinc/cp-kafka-rest:7.5.1
depends_on:
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:29092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
flink-sql-client:
image: cnfldemos/flink-sql-client-kafka:1.19.0-scala_2.12-java17
hostname: flink-sql-client
container_name: flink-sql-client
depends_on:
- flink-jobmanager
environment:
FLINK_JOBMANAGER_HOST: flink-jobmanager
volumes:
- ./settings/:/settings
flink-jobmanager:
image: cnfldemos/flink-kafka:1.19.0-scala_2.12-java17
hostname: flink-jobmanager
container_name: flink-jobmanager
ports:
- 9081:9081
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
rest.bind-port: 9081
flink-taskmanager:
image: cnfldemos/flink-kafka:1.19.0-scala_2.12-java17
hostname: flink-taskmanager
container_name: flink-taskmanager
depends_on:
- flink-jobmanager
command: taskmanager
scale: 1
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 10Crie um diretório chamado confluent/confluent-platform-flink-docker e salve o arquivo docker-compose.yml nele.
Acesse o diretório e execute o comando:
sudo docker compose up -dO docker começará a baixar as imagens. Essa parte é um pouco demorada, portanto, tenha paciência e aguarde o término.
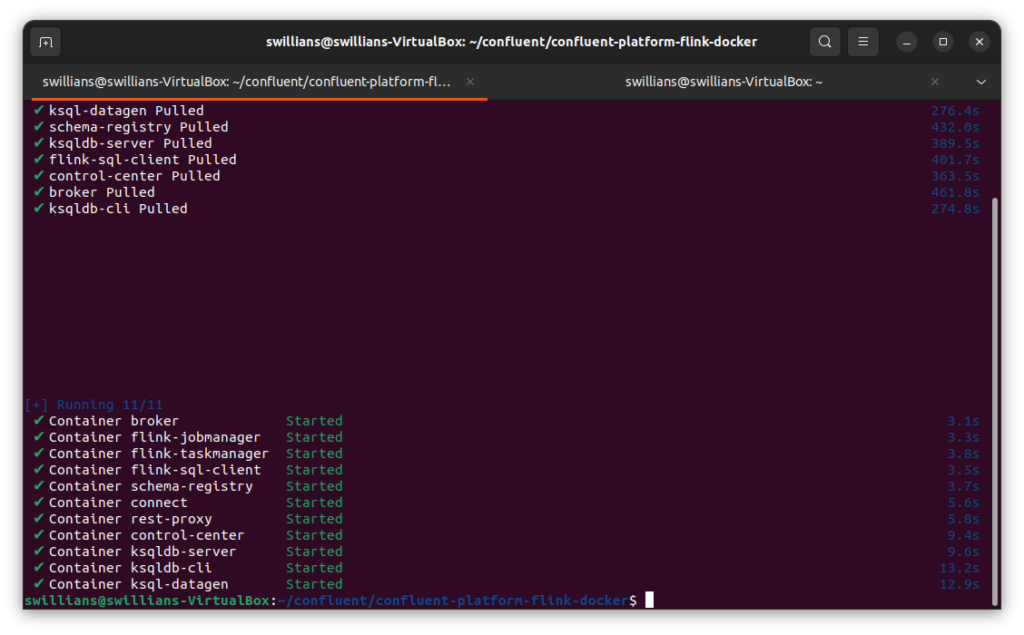
Após o download, ele começará a executar os containers…
Agora vamos verificar se o Control Center já está no ar. Para isso, acesse o endereço http://localhost:9021
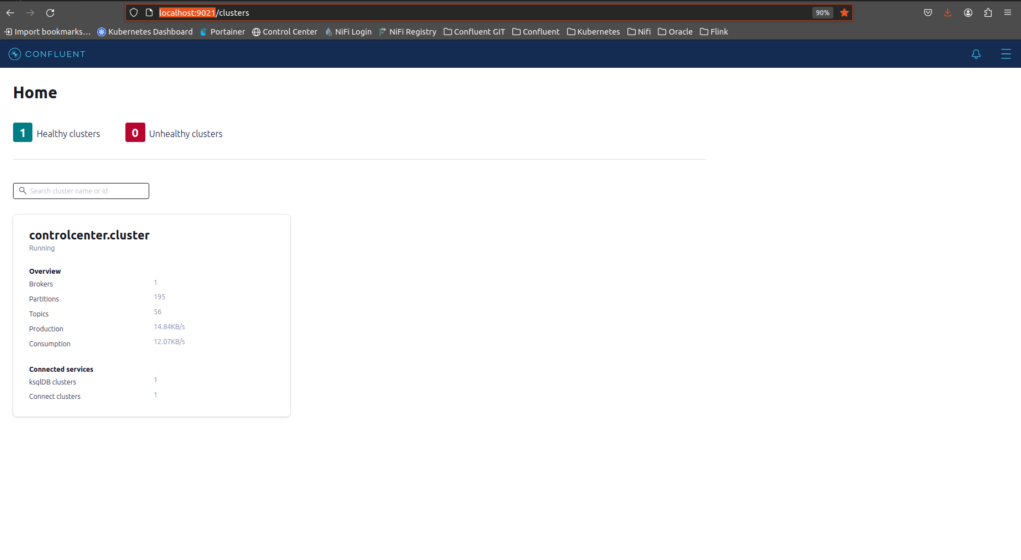
Clique em controlcenter.cluster.
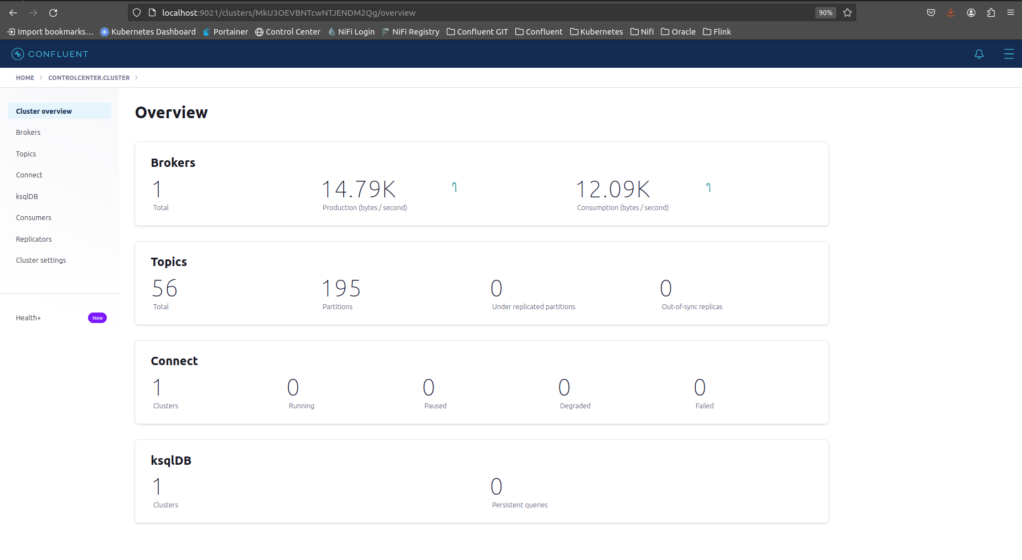
A Confluent platform está executando com sucesso !
Agora vamos testar o Flink, acessando o Apache Flink Dashboard. Para isso, acesse o endereço http://localhost:9081.
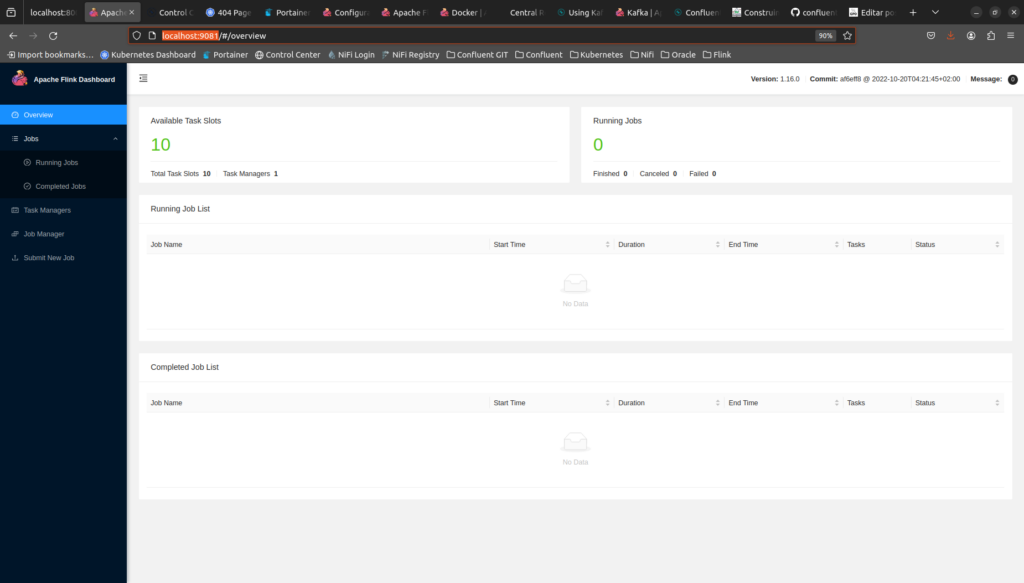
Agora, como último teste, vamos acessar o SQL Client do Flink. Para isso, execute o comando abaixo:
sudo docker compose exec flink-sql-client sql-client.sh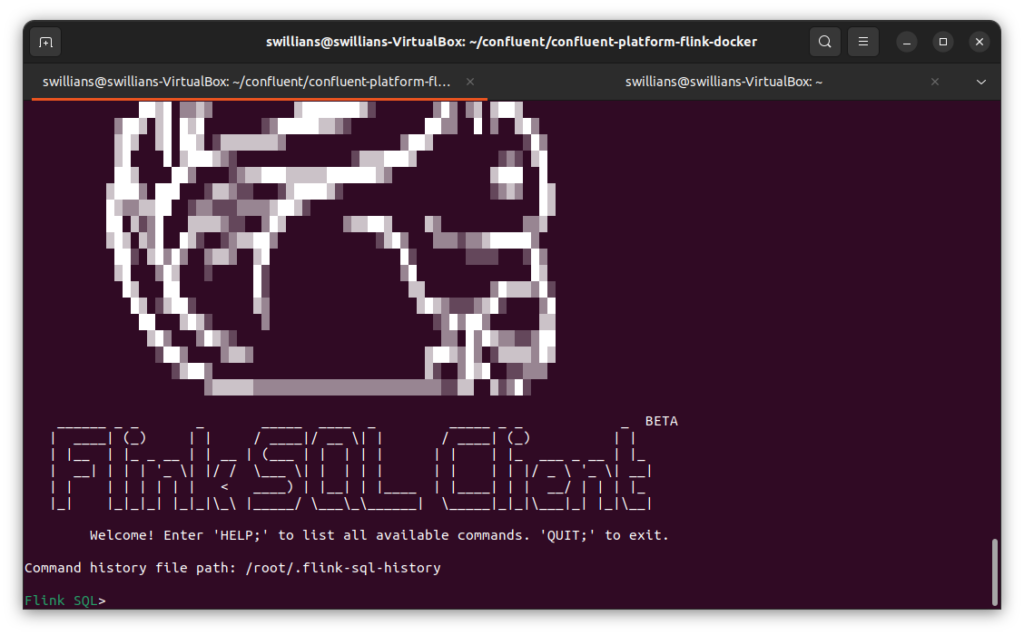
Perfeito ! Nosso ambiente foi instalado com sucesso !!!
No nosso próximo encontro, vamos embarcar em uma missão especial: a instalação do conector Spooldir no Kafka. Esse conector é uma peça-chave, pois ele será responsável por ler arquivos de texto no formato CSV e transformá-los em dados valiosos para o nosso tópico. Esse tópico, por sua vez, será o alicerce para realizarmos nossos experimentos e testes com o Flink.
A próxima etapa promete ser tão informativa quanto prática. Até breve !
Abraço !
Referências
Quando vem a segunda parte ?
Já está disponível Gilson !
https://www.profissionaloracle.com.br/2024/05/14/kafka-confluent-platform-e-apache-flink-uma-combinacao-perfeita-parte-ii/